大家好,我是二哥。在文章《特洛伊木马-图解VXLAN容器网络通信方案》里,二哥画了下面这张鸟瞰大图。它把基于Flannel VXLAN模式实现的K8s Overlay网络模型所需要的各类网路设备放在了一起,主要突出的是这些设备之间的数据流向。但那篇文章有些许缺点(凡尔赛一下):
-
配图没有很好地显示这些网络设备和协议栈之间的相对位置关系。
-
对于容器来说,network namespace是一个非常重要的隔离手段,这张图没有很好地展示出这个重要性。
-
文章没有交代清楚一个重要的网络包封装节点:根据本机路由,cni0把从Pod a发过来的请求转至flannel.1后,到底发生了什么?
-
配图是为Flannel VXLAN模式准备的。我们知道为了效率,VXLAN模式下,所有的封装和解封装都是由VXLAN内核模块完成的。因为在内核,看不见摸不着就比较抽象。本来K8s Overlay网络模型就已经挺复杂了,加上这个更加不利于我们学习理解。
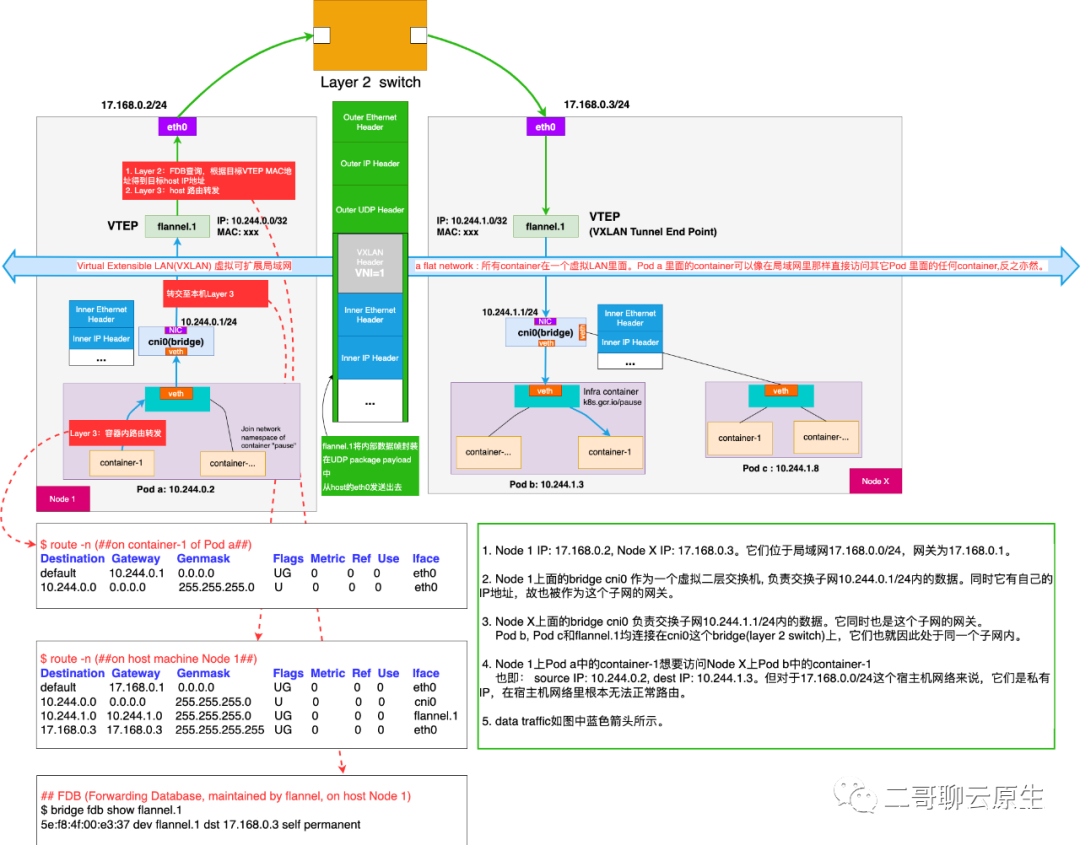 编辑搜图
编辑搜图
图 1:基于flannel实现的Overlay网络模型设备关系图
新视角
二哥真是一个贴心的人,我特地画了下面这张图。换了一个视角,它突出了几个重要的方面:
-
每个Pod都有自己的network namespace,因而有属于它自己的routing table + iptables,这在图中 1.1 ~ 1.3 以及 2.9 ~ 2.11 这两条data path上能比较清晰地看得出来。你会看到在每个Node上都出现了若干个routing table + iptables,这很好解释,因为这个Node上有多个network namespace。
-
为了强调容器本质上也是一个进程,我将每个Pod里面的container特意画到最上面的用户态的位置。
-
可以在Link Layer这一层看到有若干种网络设备:veth、bridge、eth0、tun。它们都是组成Overlay网络模型不可或缺的关键设备。但无论它们所司何职,都必须要统一位于Link Layer。嗯,找准自己的位置很重要。
-
这张图是为Flannel UDP模式准备的。通过将图1中的VXLAN内核模块拆解成tun设备和flannel daemon,并将它们挪动到用户态,我们可以非常清晰地看到进行数据封装、解封的确切地点以及数据的流向。虽然因为效率问题,Flannel UDP模式已经不具备工程价值,但对我们学习来说,却是极好的。
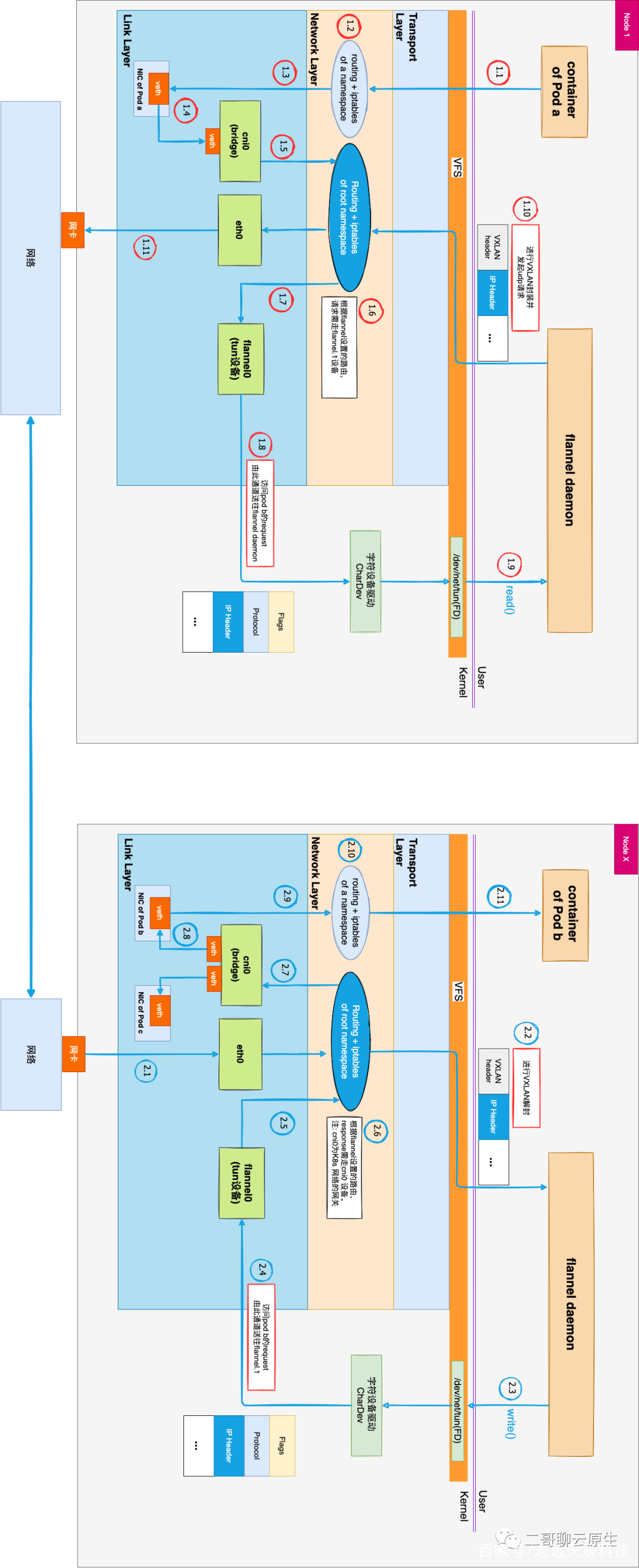 编辑搜图
编辑搜图
图 2:设备和协议栈关系图
图2中Pod a的IP是10.244.0.2,Pod b的IP是10.244.1.3。左图中bridge cni0配有IP地址10.244.0.1,右图中bridge的IP是10.244.1.1。一切都和图1保持一样,只是换了个视角。我们的故事从左图 Pod a中的容器发起请求开始,请求的对象是右图 Pod b。也即src IP是10.244.0.2,dest IP是10.244.1.3。1.x 代表的是在Node 1上面,从容器内产生网络包到它离开网卡的完整流程。而相应地,2.x表示在Node X上,从网卡收到请求到这个请求最终送至Pod b中容器的完整流程。这张图没有画出响应流程,故图中箭头都是单向的。其实把所有的箭头反过来就是响应流程了。此去路途山路十八弯,客官坐好,我要发车了。
发生在Pod里的故事
1.2 这个位置routing table + iptables用来控制Pod内容器的网络路由。对于Pod a的容器而言,10.244.0.1扮演了网关的角色,而10.244.0.1正是图中 cni0 这个bridge。下面是 1.2 处的路由表。
# on container of Pod a $ route -n Destination Gateway Genmask Flags Metric Ref Use Iface default 10.244.0.1 0.0.0.0 UG 0 0 0 eth0 10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth01.2.3.4.5.
有一个概念再次强调一遍:虽然 1.2 和 1.6 处有两个分属不同network namespace的路由表,但TCP/IP协议栈却只有一份。也即对于协议栈而言,它只是在处理相同数据结构的不同数据实例罢了。
完美转场
当网络包沿着 1.4 流进bridge cni0后,藉由bridge的一个特殊功能,实现了网络包从一个network namespace完美跳转到另一个network namespace的神奇效果。
bridge即为网桥,它的行为类似二层交换机。如果网络包的目的 MAC 地址为网桥本身,并且网桥设置了 IP 地址的话,那么bridge就认为该网络包应该是发往创建该网桥的那台主机。因而这个网络包将不会被bridge转发到任何设备,而是直接交给上层(三层)协议栈去处理。处理的过程会涉及到基于本机路由表的路由查询。1.6 处的路由表开始发挥它的作用。因为目的IP是10.244.1.3,所以网络包需要被送往tun设备flannel.1。
# on host machine Node 1 $ route -n Destination Gateway Genmask Flags Metric Ref Use Iface default 17.168.0.1 0.0.0.0 UG 0 0 0 eth0 10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1 17.168.0.3 17.168.0.3 255.255.255.255 UG 0 0 0 eth01.2.3.4.5.6.7.
其实在 1.4 ~ 1.5 这里涉及到更多的有趣问题。比如网络包在veth pair之间是如何流转的?网络包在bridge内部是如何处理的?但这并非本文的重点,以后二哥再聊。不过我先把图3 放上来。老铁们在我的文章《看图写话:聊聊veth数据流》见过这张图,我在那篇文章的配图基础上加上了bridge的处理细节,后面有机会二哥会细聊这个地方。
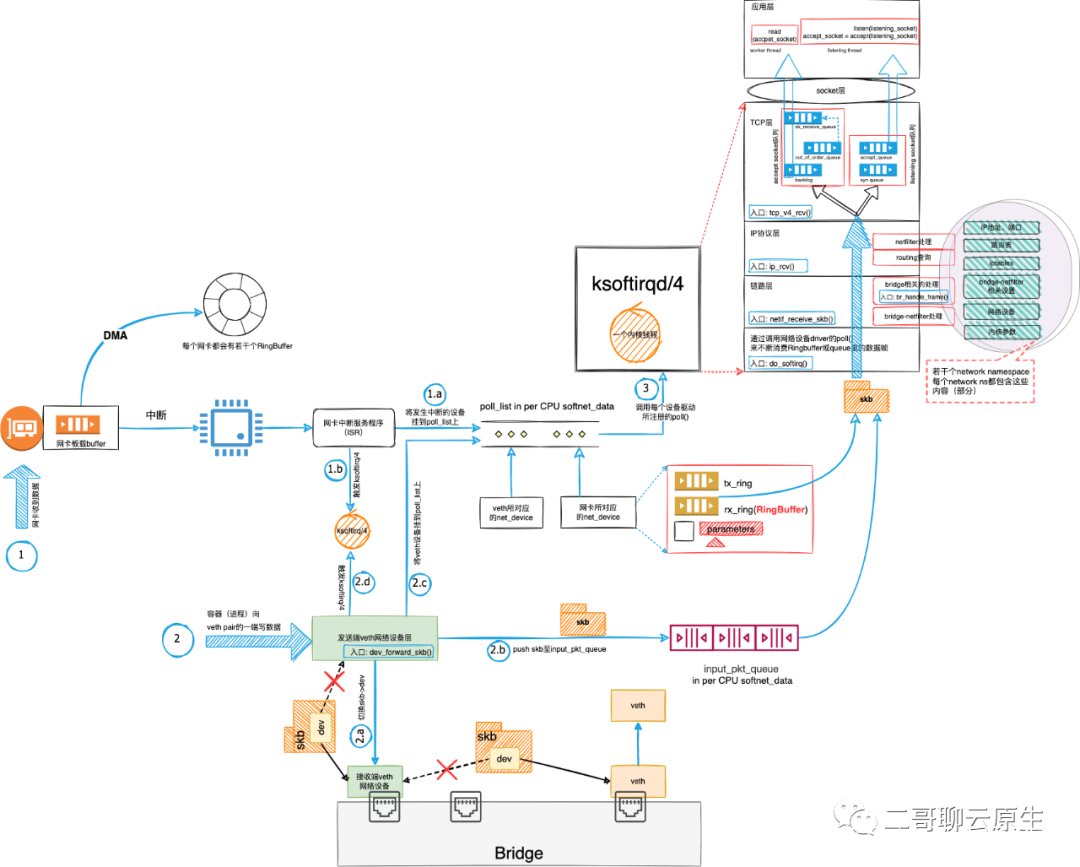 编辑搜图
编辑搜图
图 3:veth + bridge网络包接收流程中,Bridge处理细节
反着来一遍
当Node X收到从Node 1发来的数据后,沿着 2.1 一路兜兜转转,绕绕弯弯来到 2.11 ,Pod b也就收到了Pod a发出的请求。你也看到了,除了箭头方向不同外,图2的左、右两部分几乎完全一样。是的,实际上画图的时候,我就是粘贴、拷贝加批量改箭头方向这样搞的。
右图中 2.6 和 2.10 位置处的路由表和iptables的作用和左图相同,就不再赘述了。虽然路途比较艰辛,但总归是完整到达了,本篇也就到此结束了