IO性能的发展,明显落后于CPU的发展。Memchached也好,NoSql也好,这些流行技术的背后都在直接或者间接地回避IO瓶颈,从而提高系统性能
一、IO 系统的分层
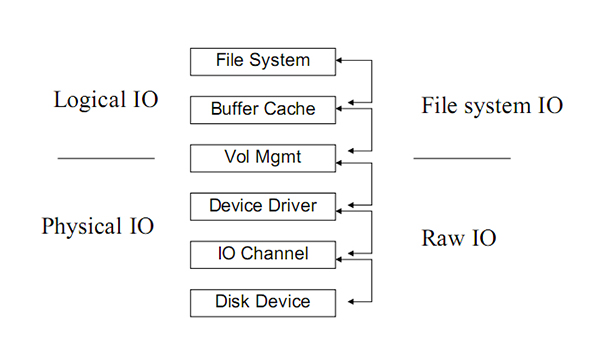
上图层次比较多,但总的就是三部分。磁盘(存储)、VM(卷管理)和文件系统。专有名词不好理解,打个比方说:磁盘就相当于一块待用的空地;LVM相当于空地上的围墙(把空地划分成多个部分);文件系统则相当于每块空地上建的楼房(决定了有多少房间、房屋编号如何,能容纳多少人住);而房子里面住的人,则相当于系统里面存的数据。
1.1 文件系统—数据如何存放?
对应了上图的File System和Buffer Cache。
File System(文件系统):解决了空间管理的问题,即:数据如何存放、读取。
Buffer Cache:解决数据缓冲的问题。对读,进行cache,即:缓存经常要用到的数据;对写,进行buffer,缓冲一定数据以后,一次性进行写入。
1.2 VM—磁盘空间不足了怎么办?
对应上图的Vol Mgmt。
VM其实跟IO没有必然联系。他是处于文件系统和磁盘(存储)中间的一层。VM屏蔽了底层磁盘对上层文件系统的影响。当没有VM的时候,文件系统直接使用存储上的地址空间,因此文件系统直接受限于物理硬盘,这时如果发生磁盘空间不足的情况,对应用而言将是一场噩梦,不得不新增硬盘,然后重新进行数据复制。而VM则可以实现动态扩展,而对文件系统没有影响。另外,VM也可以把多个磁盘合并成一个磁盘,对文件系统呈现统一的地址空间,这个特性的杀伤力不言而喻。
1.3 存储—数据放在哪儿?如何访问?如何提高IO速度?
对应上图的Device Driver、IO Channel和Disk Device
数据最终会放在这里,因此,效率、数据安全、容灾是这里需要考虑的问题。而提高存储的性能,则可以直接提高物理IO的性能。
1.4 Logical IO vs Physical IO
逻辑IO是操作系统发起的IO,这个数据可能会放在磁盘上,也可能会放在内存(文件系统的Cache)里。
物理IO是设备驱动发起的IO,这个数据最终会落在磁盘上。
逻辑IO和物理IO不是一一对应的。
二、IO 模型
这部分的东西在网络编程经常能看到,不过在所有IO处理中都是类似的。
2.1 IO请求的两个阶段
等待资源阶段:IO请求一般需要请求特殊的资源(如磁盘、RAM、文件),当资源被上一个使用者使用没有被释放时,IO请求就会被阻塞,直到能够使用这个资源。
使用资源阶段:真正进行数据接收和发生。
2.2 在等待数据阶段,IO分为阻塞IO和非阻塞IO。
阻塞IO:资源不可用时,IO请求一直阻塞,直到反馈结果(有数据或超时)。
非阻塞IO:资源不可用时,IO请求离开返回,返回数据标识资源不可用
2.3 在使用资源阶段,IO分为同步IO和异步IO。
同步IO:应用阻塞在发送或接收数据的状态,直到数据成功传输或返回失败。
异步IO:应用发送或接收数据后立刻返回,数据写入OS缓存,由OS完成数据发送或接收,并返回成功或失败的信息给应用。
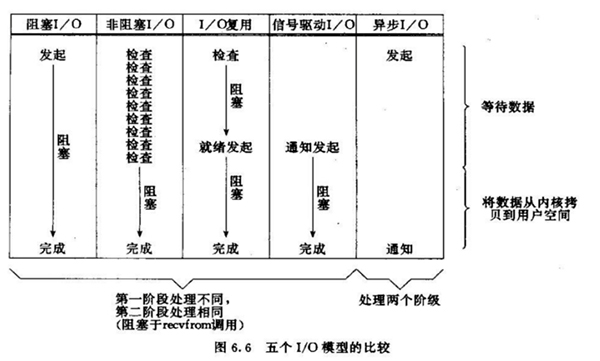
2.4 按照Unix的5个IO模型划分
- 阻塞IO
- 非阻塞IO
- IO复用
- 信号驱动的IO
- 异步IO
从性能上看,异步IO的性能无疑是最好的。
2.5 各种IO的特点
阻塞IO:使用简单,但随之而来的问题就是会形成阻塞,需要独立线程配合,而这些线程在大多数时候都是没有进行运算的。
非阻塞IO:采用轮询方式,不会形成线程的阻塞。
同步IO:同步IO保证一个IO操作结束之后才会返回,因此同步IO效率会低一些,但是对应用来说,编程方式会简单。
异步IO:由于异步IO请求只是写入了缓存,从缓存到硬盘是否成功不可知,因此异步IO相当于把一个IO拆成了两部分,一是发起请求,二是获取处理结果。因此,对应用来说增加了复杂性。但是异步IO的性能是所有很好的,而且异步的思想贯穿了IT系统放放面面。
详细参考:Linux网络IO精华指南
三、最重要的三个指标
3.1 IOPS
IOPS,即每秒钟处理的IO请求数量。IOPS是随机访问类型业务(OLTP类)很重要的一个参考指标。
3.12 一块物理硬盘能提供多少IOPS?
从磁盘上进行数据读取时,比较重要的几个时间是:寻址时间(找到数据块的起始位置),旋转时间(等待磁盘旋转到数据块的起始位置),传输时间(读取数据的时间和返回的时间)。其中寻址时间是固定的(磁头定位到数据的存储的扇区即可),旋转时间受磁盘转速的影响,传输时间受数据量大小的影响和接口类型的影响(不同的硬盘接口速度不同),但是在随机访问类业务中,他的时间也很少。因此,在硬盘接口相同的情况下,IOPS主要受限于寻址时间和传输时间。以一个15K的硬盘为例,寻址时间固定为4ms,旋转时间为60s/15000*1/2(最多转半圈)=2ms,一般计算IOPS都忽略传输时间。1000ms/6ms=167个IOPS。
3.13 OS的一次IO请求对应物理硬盘一个IO吗?
在没有文件系统、没有VM(卷管理)、没有RAID、没有存储设备的情况下,这个答案还是成立的。但是当这么多中间层加进去以后,这个答案就不是这样了。物理硬盘提供的IO是有限的,也是整个IO系统存在瓶颈的最大根源。所以,如果一块硬盘不能提供,那么多块在一起并行处理,这不就行了吗?确实是这样的。可以看到,越是高端的存储设备的cache越大,硬盘越多,一方面通过cache异步处理IO,另一方面通过盘数增加,尽可能把一个OS的IO分布到不同硬盘上,从而提高性能。文件系统则是在cache上会影响,而VM则可能是一个IO分布到多个不同设备上(Striping)。
所以,一个OS的IO在经过多个中间层以后,发生在物理磁盘上的IO是不确定的。可能是一对一个,也可能一个对应多个。
3.14 IOPS能算出来吗?
对单块磁盘的IOPS的计算没有没问题,但是当系统后面接的是一个存储系统时、考虑不同读写比例,IOPS则很难计算,而需要根据实际情况进行测试。主要的因素有:存储系统本身有自己的缓存。缓存大小直接影响IOPS,理论上说,缓存越大能cache的东西越多,在cache命中率保持的情况下,IOPS会越高。
RAID级别。不同的RAID级别影响了物理IO的效率。
读写混合比例。对读操作,一般只要cache能足够大,可以大大减少物理IO,而都在cache中进行;对写操作,不论cache有多大,最终的写还是会落到磁盘上。因此,100%写的IOPS要越狱小于100%的读的IOPS。同时,100%写的IOPS大致等同于存储设备能提供的物理的IOPS。
一次IO请求数据量的多少。一次读写1KB和一次读写1MB,显而易见,结果是完全不同的。
当时上面N多因素混合在一起以后,IOPS的值就变得扑朔迷离了。所以,一般需要通过实际应用的测试才能获得。
3.2 IO Response Time
即IO的响应时间。IO响应时间是从操作系统内核发出一个IO请求到接收到IO响应的时间。因此,IO Response time除了包括磁盘获取数据的时间,还包括了操作系统以及在存储系统内部IO等待的时间。一般看,随IOPS增加,因为IO出现等待,IO响应时间也会随之增加。对一个OLTP系统,10ms以内的响应时间,是比较合理的。下面是一些IO性能示例:
一个8K的IO会比一个64K的IO速度快,因为数据读取的少些。
一个64K的IO会比8个8K的IO速度快,因为前者只请求了一个IO而后者是8个IO。
串行IO会比随机IO快,因为串行IO相对随机IO说,即便没有Cache,串行IO在磁盘处理上也会少些操作。
需要注意,IOPS与IO Response Time有着密切的联系。一般情况下,IOPS增加,说明IO请求多了,IO Response Time会相应增加。但是会出现IOPS一直增加,但是IO Response Time变得非常慢,超过20ms甚至几十ms,这时候的IOPS虽然还在提高,但是意义已经不大,因为整个IO系统的服务时间已经不可取。
3.3 Throughput
为吞吐量。这个指标衡量标识了最大的数据传输量。如上说明,这个值在顺序访问或者大数据量访问的情况下会比较重要。尤其在大数据量写的时候。
吞吐量不像IOPS影响因素很多,吞吐量一般受限于一些比较固定的因素,如:网络带宽、IO传输接口的带宽、硬盘接口带宽等。一般他的值就等于上面几个地方中某一个的瓶颈。
3.4 一些概念
3.41 IO Chunk Size
即单个IO操作请求数据的大小。一次IO操作是指从发出IO请求到返回数据的过程。IO Chunk Size与应用或业务逻辑有着很密切的关系。比如像Oracle一类数据库,由于其block size一般为8K,读取、写入时都此为单位,因此,8K为这个系统主要的IO Chunk Size。IO Chunk Size小,考验的是IO系统的IOPS能力;IO Chunk Size大,考验的时候IO系统的IO吞吐量。
3.42 Queue Deep
熟悉数据库的人都知道,SQL是可以批量提交的,这样可以大大提高操作效率。IO请求也是一样,IO请求可以积累一定数据,然后一次提交到存储系统,这样一些相邻的数据块操作可以进行合并,减少物理IO数。而且Queue Deep如其名,就是设置一起提交的IO请求数量的。一般Queue Deep在IO驱动层面上进行配置。
Queue Deep与IOPS有着密切关系。Queue Deep主要考虑批量提交IO请求,自然只有IOPS是瓶颈的时候才会有意义,如果IO都是大IO,磁盘已经成瓶颈,Queue Deep意义也就不大了。一般来说,IOPS的峰值会随着Queue Deep的增加而增加(不会非常显著),Queue Deep一般小于256。
3,43 随机访问(随机IO)、顺序访问(顺序IO)
随机访问的特点是每次IO请求的数据在磁盘上的位置跨度很大(如:分布在不同的扇区),因此N个非常小的IO请求(如:1K),必须以N次IO请求才能获取到相应的数据。
顺序访问的特点跟随机访问相反,它请求的数据在磁盘的位置是连续的。当系统发起N个非常小的IO请求(如:1K)时,因为一次IO是有代价的,系统会取完整的一块数据(如4K、8K),所以当第一次IO完成时,后续IO请求的数据可能已经有了。这样可以减少IO请求的次数。这也就是所谓的预取。
随机访问和顺序访问同样是有应用决定的。如数据库、小文件的存储的业务,大多是随机IO。而视频类业务、大文件存取,则大多为顺序IO。
3.44 选取合理的观察指标:
以上各指标中,不用的应用场景需要观察不同的指标,因为应用场景不同,有些指标甚至是没有意义的。
随机访问和IOPS: 在随机访问场景下,IOPS往往会到达瓶颈,而这个时候去观察Throughput,则往往远低于理论值。
顺序访问和Throughput:在顺序访问的场景下,Throughput往往会达到瓶颈(磁盘限制或者带宽),而这时候去观察IOPS,往往很小。
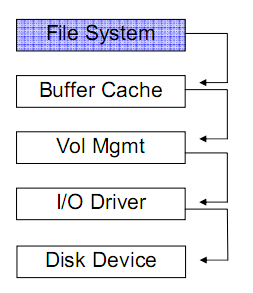
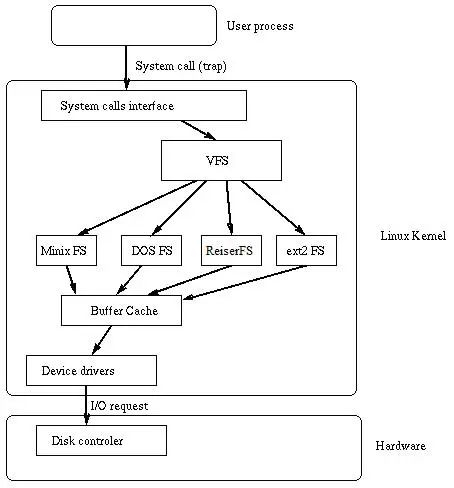
文件系统各有不同,其最主要的目标就是解决磁盘空间的管理问题,同时提供高效性、安全性。如果在分布式环境下,则有相应的分布式文件系统。Linux上有ext系列,Windows上有Fat和NTFS。如图为一个linux下文件系统的结构。
其中VFS(Virtual File System)是Linux Kernel文件系统的一个模块,简单看就是一个Adapter,对下屏蔽了下层不同文件系统之间的差异,对上为操作系统提供了统一的接口.
中间部分为各个不同文件系统的实现。
再往下是Buffer Cache和Driver。
详细学习:深入理解Linux 的Page Cache
四、文件系统的结构
各种文件系统实现方式不同,因此性能、管理性、可靠性等也有所不同。下面为Linux Ext2(Ext3)的一个大致文件系统的结构。
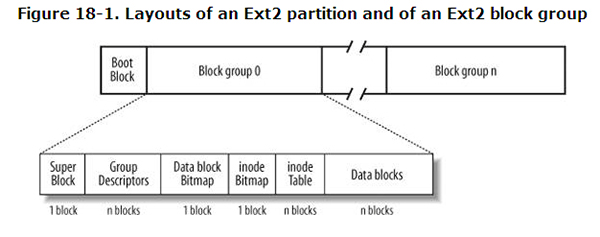
Boot Block存放了引导程序。
Super Block存放了整个文件系统的一些全局参数,如:卷名、状态、块大小、块总数。他在文件系统被mount时读入内存,在umount时被释放。
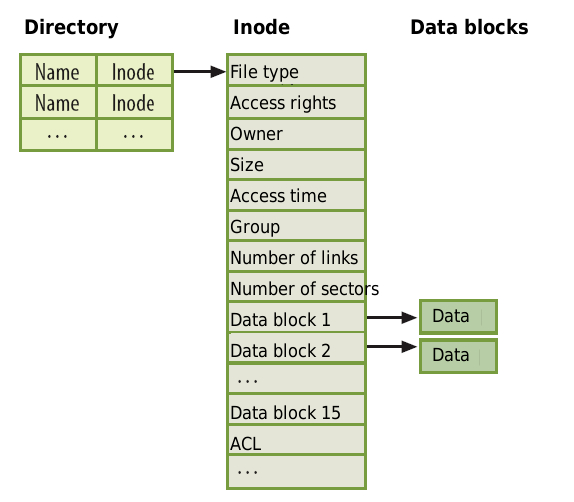
上图描述了Ext2文件系统中很重要的三个数据结构和他们之间的关系。
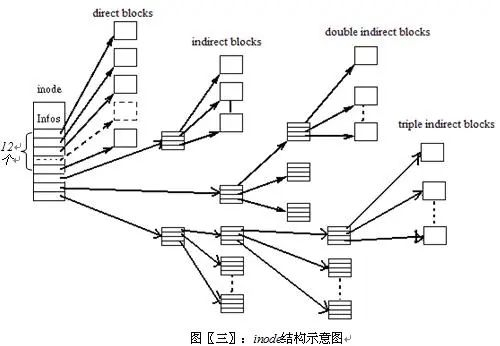
Inode:Inode是文件系统中最重要的一个结构。如图,他里面记录了文件相关的所有信息,也就是我们常说的meta信息。包括:文件类型、权限、所有者、大小、atime等。Inode里面也保存了指向实际文件内容信息的索引。其中这种索引分几类:
直接索引:直接指向实际内容信息,公有12个。因此如果,一个文件系统block size为1k,那么直接索引到的内容最大为12k
- 间接索引
- 两级间接索引
- 三级间接索引
如图:
Directory代表了文件系统中的目录,包括了当前目录中的所有Inode信息。其中每行只有两个信息,一个是文件名,一个是其对应的Inode。需要注意,Directory不是文件系统中的一个特殊结构,他实际上也是一个文件,有自己的Inode,而它的文件内容信息里面,包括了上面看到的那些文件名和Inode的对应关系。如下图:
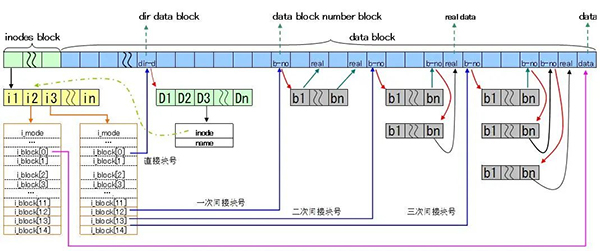
Data Block即存放文件的时间内容块。Data Block大小必须为磁盘的数据块大小的整数倍,磁盘一般为512字节,因此Data Block一般为1K、2K、4K。
Buffer & Cache
虽然Buffer和Cache放在一起了,但是在实际过程中Buffer和Cache是完全不同了。Buffer一般对于写而言,也叫“缓冲区”,缓冲使得多个小的数据块能够合并成一个大数据块,一次性写入;Cache一般对于读而且,也叫“缓存”,避免频繁的磁盘读取。如图为Linux的free命令,其中也是把Buffer和Cache进行区分,这两部分都算在了free的内存。

Buffer Cache
Buffer Cache中的缓存,本质与所有的缓存都是一样,数据结构也是类似,下图为VxSF的一个Buffer Cache结构。
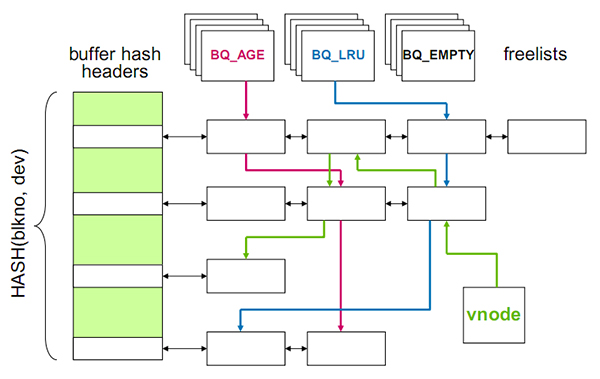
这个数据结构与memcached和Oracle SGA的buffer何等相似。左侧的hash chain完成数据块的寻址,上方的的链表记录了数据块的状态。
Buffer vs Direct I/O
文件系统的Buffer和Cache在某些情况下确实提高了速度,但是反之也会带来一些负面影响。一方面文件系统增加了一个中间层,另外一方面,当Cache使用不当、配置不好或者有些业务无法获取cache带来的好处时,cache则成为了一种负担。
适合Cache的业务:串行的大数据量业务,如:NFS、FTP。
不适合Cache的业务:随机IO的业务。如:Oracle,小文件读取。
块设备、字符设备、裸设备
这几个东西看得很晕,找了一些资料也没有找到很准确的说明。
从硬件设备的角度来看,
- 块设备就是以块(比如磁盘扇区)为单位收发数据的设备,它们支持缓冲和随机访问(不必顺序读取块,而是可以在任何时候访问任何块)等特性。块设备包括硬盘、CD-ROM 和 RAM 盘。
- 字符设备则没有可以进行物理寻址的媒体。字符设备包括串行端口和磁带设备,只能逐字符地读取这些设备中的数据。
从操作系统的角度看(对应操作系统的设备文件类型的b和c),
# ls -l /dev/*lvbrw------- 1 root system 22, 2 May 15 2007 lv crw------- 2 root system 22, 2 May 15 2007 rlv1.2.3.
- 块设备能支持缓冲和随机读写。即读取和写入时,可以是任意长度的数据。最小为1byte。对块设备,你可以成功执行下列命令:dd if=/dev/zero of=/dev/vg01/lv bs=1 count=1。即:在设备中写入一个字节。硬件设备是不支持这样的操作的(最小是512),这个时候,操作系统首先完成一个读取(如1K,操作系统最小的读写单位,为硬件设备支持的数据块的整数倍),再更改这1k上的数据,然后写入设备。
- 字符设备只能支持固定长度数据的读取和写入,这里的长度就是操作系统能支持的最小读写单位,如1K,所以块设备的缓冲功能,这里就没有了,需要使用者自己来完成。由于读写时不经过任何缓冲区,此时执行dd if=/dev/zero of=/dev/vg01/lv bs=1 count=1,这个命令将会出错,因为这里的bs(block size)太小,系统无法支持。如果执行dd if=/dev/zero of=/dev/vg01/lv bs=1024 count=1,则可以成功。这里的block size有OS内核参数决定。
如上,相比之下,字符设备在使用更为直接,而块设备更为灵活。文件系统一般建立在块设备上,而为了追求高性能,使用字符设备则是更好的选择,如Oracle的裸设备使用。
裸设备
裸设备也叫裸分区,就是没有经过格式化、没有文件系统的一块存储空间。可以写入二进制内容,但是内容的格式、其中信息的组织等问题,需要使用它的人来完成。文件系统就是建立在裸设备之上,并完成裸设备空间的管理。
CIO
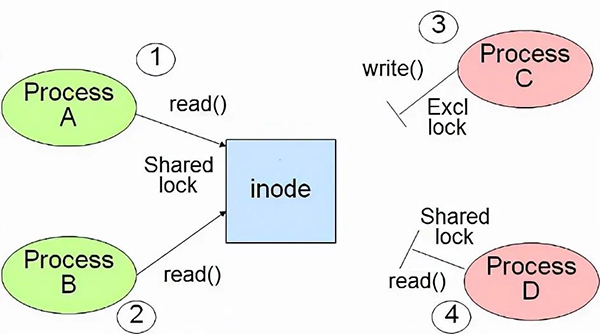
CIO即并行IO(Concurrent IO)。在文件系统中,当某个文件被多个进程同时访问时,就出现了Inode竞争的问题。一般地,读操作使用的共享锁,即:多个读操作可以并发进行,而写操作使用排他锁。当锁被写进程占用时,其他所有操作均阻塞。因此,当这样的情况出现时,整个应用的性能将会大大降低。如图:
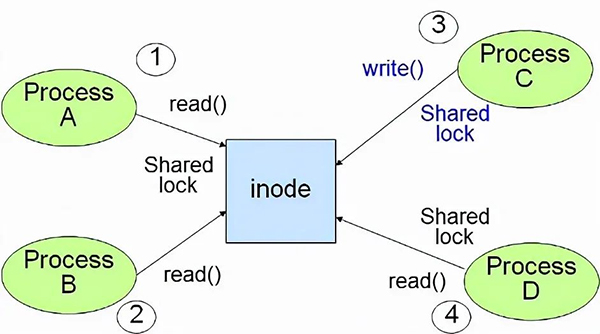
CIO就是为了解决这个问题。而且CIO带来的性能提高直逼裸设备。当文件系统支持CIO并开启CIO时,CIO默认会开启文件系统的Direct IO,即:让IO操作不经过Buffer直接进行底层数据操作。由于不经过数据Buffer,在文件系统层面就无需考虑数据一致性的问题,因此,读写操作可以并行执行。
在最终进行数据存储的时候,所有操作都会串行执行,CIO把这个事情交个了底层的driver。
LVM(逻辑卷管理),位于操作系统和硬盘之间,LVM屏蔽了底层硬盘带来的复杂性。最简单的,LVM使得N块硬盘在OS看来成为一块硬盘,大大提高了系统可用性。
LVM的引入,使得文件系统和底层磁盘之间的关系变得更为灵活,而且更方便关系。LVM有以下特点:
- 统一进行磁盘管理。按需分配空间,提供动态扩展。
- 条带化(Striped)
- 镜像(mirrored)
- 快照(snapshot)
LVM可以做动态磁盘扩展,想想看,当系统管理员发现应用空间不足时,敲两个命令就完成空间扩展,估计做梦都要笑醒:)
LVM的磁盘管理方式
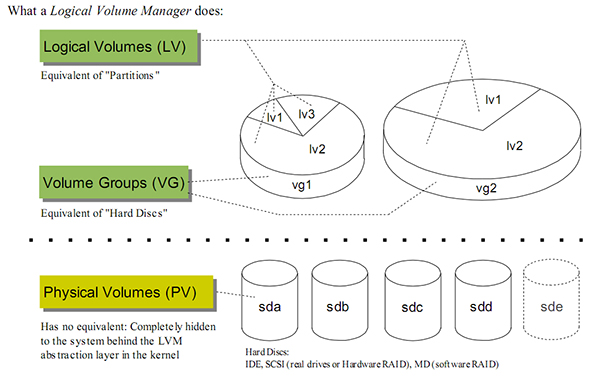
LVM中有几个很重要的概念:
- PV(physical volume):物理卷。在LVM中,一个PV对应就是操作系统能看见的一块物理磁盘,或者由存储设备分配操作系统的lun。一块磁盘唯一对应一个PV,PV创建以后,说明这块空间可以纳入到LVM的管理。创建PV时,可以指定PV大小,即可以把整个磁盘的部分纳入PV,而不是全部磁盘。这点在表面上看没有什么意义,但是如果主机后面接的是存储设备的话就很有意义了,因为存储设备分配的lun是可以动态扩展的,只有当PV可以动态扩展,这种扩展性才能向上延伸。
- VG(volume group):卷组。一个VG是多个PV的集合,简单说就是一个VG就是一个磁盘资源池。VG对上屏蔽了多个物理磁盘,上层是使用时只需考虑空间大小的问题,而VG解决的空间的如何在多个PV上连续的问题。
- LV(logical volume):逻辑卷。LV是最终可供使用卷,LV在VG中创建,有了VG,LV创建是只需考虑空间大小等问题,对LV而言,他看到的是一直联系的地址空间,不用考虑多块硬盘的问题。
有了上面三个,LVM把单个的磁盘抽象成了一组连续的、可随意分配的地址空间。除上面三个概念外,还有一些其他概念:
- PE(physical extend): 物理扩展块。LVM在创建PV,不会按字节方式去进行空间管理。而是按PE为单位。PE为空间管理的最小单位。即:如果一个1024M的物理盘,LVM的PE为4M,那么LVM管理空间时,会按照256个PE去管理。分配时,也是按照分配了多少PE、剩余多少PE考虑。
- LE(logical extend):逻辑扩展块。类似PV,LE是创建LV考虑,当LV需要动态扩展时,每次最小的扩展单位。
对于上面几个概念,无需刻意去记住,当你需要做这么一个东西时,这些概念是自然而然的。PV把物理硬盘转换成LVM中对于的逻辑(解决如何管理物理硬盘的问题),VG是PV的集合(解决如何组合PV的问题),LV是VG上空间的再划分(解决如何给OS使用空间的问题);而PE、LE则是空间分配时的单位。
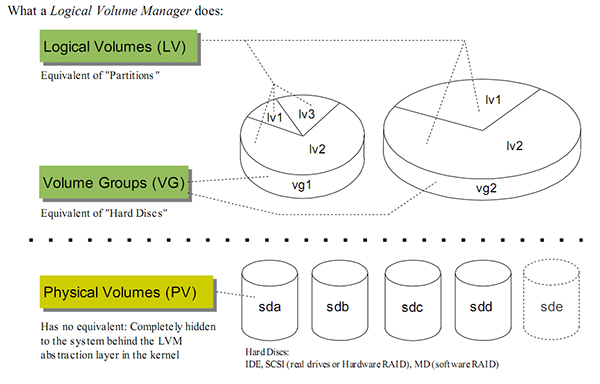
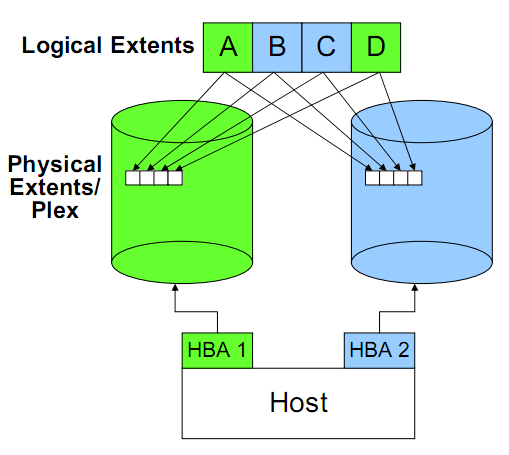
如图,为两块18G的磁盘组成了一个36G的VG。此VG上划分了3个LV。其PE和LE都为4M。其中LV1只用到了sda的空间,而LV2和LV3使用到了两块磁盘。
串联、条带化、镜像
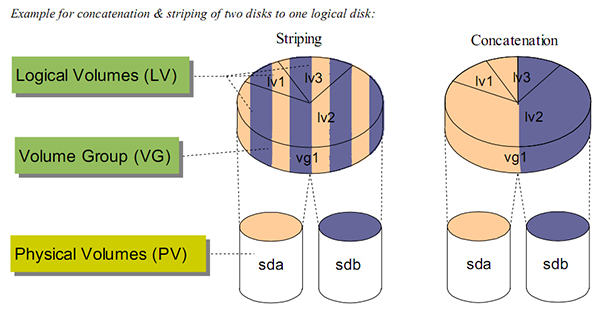
串联(Concatenation): 按顺序使用磁盘,一个磁盘使用完以后使用后续的磁盘。
条带化(Striping): 交替使用不同磁盘的空间。条带化使得IO操作可以并行,因此是提高IO性能的关键。另外,Striping也是RAID的基础。如:VG有2个PV,LV做了条带数量为2的条带化,条带大小为8K,那么当OS发起一个16K的写操作时,那么刚好这2个PV对应的磁盘可以对整个写入操作进行并行写入。
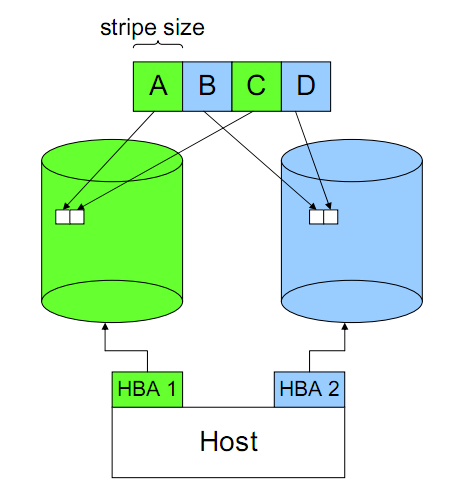
Striping带来好处有:
并发进行数据处理。读写操作可以同时发送在多个磁盘上,大大提高了性能。
Striping带来的问题:
- 数据完整性的风险。Striping导致一份完整的数据被分布到多个磁盘上,任何一个磁盘上的数据都是不完整,也无法进行还原。一个条带的损坏会导致所有数据的失效。因此这个问题只能通过存储设备来弥补。
- 条带大小的设定很大程度决定了Striping带来的好处。如果条带设置过大,一个IO操作最终还是发生在一个磁盘上,无法带来并行的好处;当条带设置国小,本来一次并行IO可以完成的事情会最终导致了多次并行IO。
镜像(mirror)
如同名字。LVM提供LV镜像的功能。即当一个LV进行IO操作时,相同的操作发生在另外一个LV上。这样的功能为数据的安全性提供了支持。如图,一份数据被同时写入两个不同的PV。
使用mirror时,可以获得一些好处:
- 读取操作可以从两个磁盘上获取,因此读效率会更好些。
- 数据完整复杂了一份,安全性更高。
但是,伴随也存在一些问题:
- 所有的写操作都会同时发送在两个磁盘上,因此实际发送的IO是请求IO的2倍
- 由于写操作在两个磁盘上发生,因此一些完整的写操作需要两边都完成了才算完成,带来了额外负担。
- 在处理串行IO时,有些IO走一个磁盘,另外一些IO走另外的磁盘,一个完整的IO请求会被打乱,LVM需要进行IO数据的合并,才能提供给上层。像一些如预读的功能,由于有了多个数据获取同道,也会存在额外的负担。
快照(Snapshot)
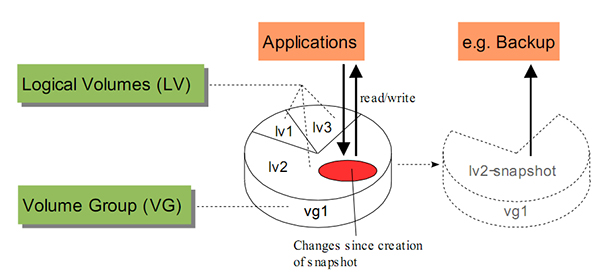
快照如其名,他保存了某一时间点磁盘的状态,而后续数据的变化不会影响快照,因此,快照是一种备份很好手段。
但是快照由于保存了某一时间点数据的状态,因此在数据变化时,这部分数据需要写到其他地方,随着而来回带来一些问题。关于这块,后续存储也涉及到类似的问题,后面再说。
这部分值得一说的是多路径问题。IO部分的高可用性在整个应用系统中可以说是最关键的,应用层可以坏掉一两台机器没有问题,但是如果IO不通了,整个系统都没法使用。如图为一个典型的SAN网络,从主机到磁盘,所有路径上都提供了冗余,以备发生通路中断的情况。
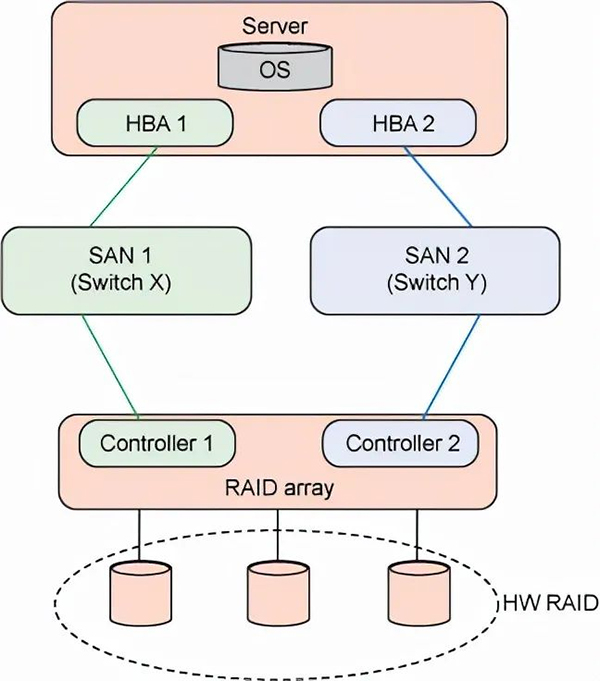
如上图结构,由于存在两条路径,对于存储划分的一个空间,在OS端会看到两个(两块磁盘或者两个lun)。可怕的是,OS并不知道这两个东西对应的其实是一块空间,如果路径再多,则OS会看到更多。还是那句经典的话,“计算机中碰到的问题,往往可以通过增加的一个中间层来解决”,于是有了多路径软件。他提供了以下特性:
- 把多个映射到同一块空间的路径合并为一个提供给主机
- 提供fail over的支持。当一条通路出现问题时,及时切换到其他通路
- 提供load balance的支持。即同时使用多条路径进行数据传送,发挥多路径的资源优势,提高系统整体带宽。
Fail over的能力一般OS也可能支持,而load balance则需要与存储配合,所以需要根据存储不同配置安装不同的多通路软件。
多路径除了解决了高可用性,同时,多条路径也可以同时工作,提高系统性能。
Raid很基础,但是在存储系统中占据非常重要的地位,所有涉及存储的书籍都会提到RAID。RAID通过磁盘冗余的方式提高了可用性和可高性,一方面增加了数据读写速度,另一方面增加了数据的安全性。
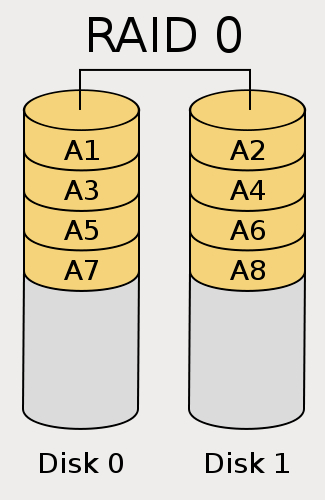
RAID 0
对数据进行条带化。使用两个磁盘交替存放连续数据。因此可以实现并发读写,但带来的问题是如果一个磁盘损坏,另外一个磁盘的数据将失去意义。RAID 0最少需要2块盘。
RAID 1
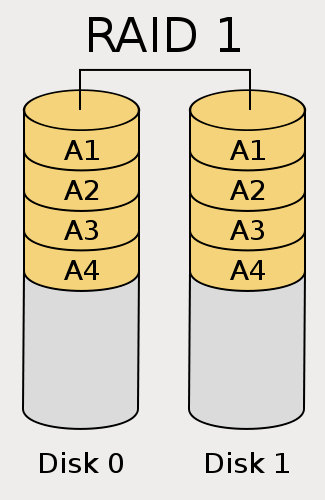
对数据进行镜像。数据写入时,相同的数据同时写入两块盘。因此两个盘的数据完全一致,如果一块盘损坏,另外一块盘可以顶替使用,RAID 1带来了很好的可靠性。同时读的时候,数据可以从两个盘上进行读取。但是RAID 1带来的问题就是空间的浪费。两块盘只提供了一块盘的空间。RAID 1最少需要2块盘。
RAID 5
使用多余的一块校验盘。数据写入时,RAID 5需要对数据进行计算,以便得出校验位。因此,在写性能上RAID 5会有损失。但是RAID 5兼顾了性能和安全性。当有一块磁盘损坏时,RAID 5可以通过其他盘上的数据对其进行恢复。
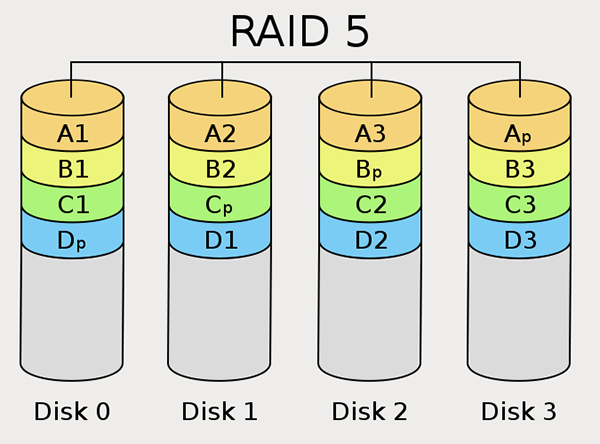
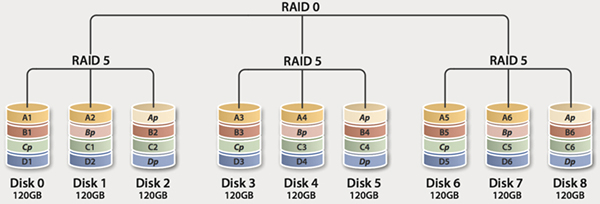
如图可以看出,右下角为p的就是校验数据。可以看到RAID 5的校验数据依次分布在不同的盘上,这样可以避免出现热点盘(因为所有写操作和更新操作都需要修改校验信息,如果校验都在一个盘做,会导致这个盘成为写瓶颈,从而拖累整体性能,RAID 4的问题)。RAID 5最少需要3块盘。
RAID 6
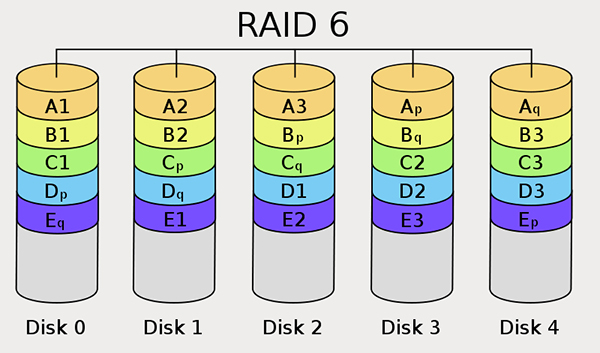
RAID 6与RAID 5类似。但是提供了两块校验盘(下图右下角为p和q的)。安全性更高,写性能更差了。RAID 0最少需要4块盘。
RAID 10(Striped mirror)
RAID 10是RAID 0 和RAID 1的结合,同时兼顾了二者的特点,提供了高性能,但是同时空间使用也是最大。RAID 10最少需要4块盘。
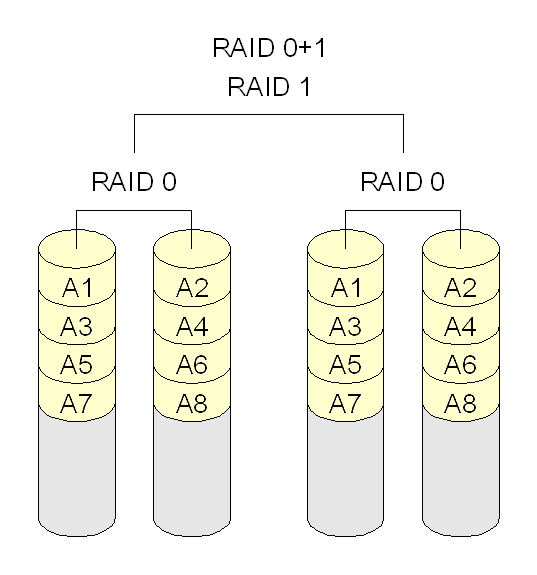
需要注意,使用RAID 10来称呼其实很容易产生混淆,因为RAID 0+1和RAID 10基本上只是两个数字交换了一下位置,但是对RAID来说就是两个不同的组成。因此,更容易理解的方式是“Striped mirrors”,即:条带化后的镜像——RAID 10;或者“mirrored stripes”,即:镜像后的条带化。比较RAID 10和RAID 0+1,虽然最终都是用到了4块盘,但是在数据组织上有所不同,从而带来问题。RAID 10在可用性上是要高于RAID 0+1的:
- RAID 0+1 任何一块盘损坏,将失去冗余。如图4块盘中,右侧一组损坏一块盘,左侧一组损坏一块盘,整个盘阵将无法使用。而RAID 10左右各损坏一块盘,盘阵仍然可以工作。
- RAID 0+1 损坏后的恢复过程会更慢。因为先经过的mirror,所以左右两组中保存的都是完整的数据,数据恢复时,需要完整恢复所以数据。而RAID 10因为先条带化,因此损坏数据以后,恢复的只是本条带的数据。如图4块盘,数据少了一半。
RAID 50
RAID 50 同RAID 10,先做条带化以后,在做RAID 5。兼顾性能,同时又保证空间的利用率。RAID 50最少需要6块盘。
总结:
- RAID与LVM中的条带化原理上类似,只是实现层面不同。在存储上实现的RAID一般有专门的芯片来完成,因此速度上远比LVM块。也称硬RAID。
- 如上介绍,RAID的使用是有风险的,如RAID 0,一块盘损坏会导致所有数据丢失。因此,在实际使用中,高性能环境会使用RAID 10,兼顾性能和安全;一般情况下使用RAID 5(RAID 50),兼顾空间利用率和性能;
DAS、SAN和NAS
DAS:有PATA、SATA、SAS等,主要是磁盘数据传输协议。
- 单台主机。在这种情况下,存储作为主机的一个或多个磁盘存在,这样局限性也是很明显的。由于受限于主机空间,一个主机只能装一块到几块硬盘,而硬盘空间时受限的,当磁盘满了以后,你不得不为主机更换更大空间的硬盘。
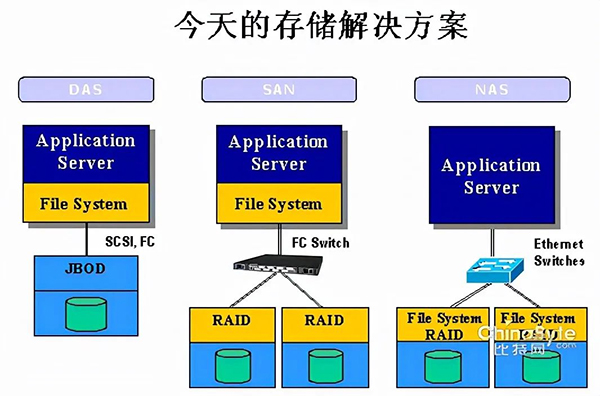
- 独立存储空间。为了解决空间的问题,于是考虑把磁盘独立出来,于是有了DAS(Direct Attached Storage),即:直连存储。DAS就是一组磁盘的集合体,数据读取和写入等也都是由主机来控制。但是,随之而来,DAS又面临了一个他无法解决的问题——存储空间的共享。接某个主机的JBOD(Just a Bunch Of Disks,磁盘组),只能这个主机使用,其他主机无法用。因此,如果DAS解决空间了,那么他无法解决的就是如果让空间能够在多个机器共享。因为DAS可以理解为与磁盘交互,DAS处理问题的层面相对更低。使用协议都是跟磁盘交互的协议
- 独立的存储网络。为了解决共享的问题,借鉴以太网的思想,于是有了SAN(Storage Area Network),即:存储网络。对于SAN网络,你能看到两个非常特点,一个就是光纤网络,另一个是光纤交换机。SAN网络由于不会之间跟磁盘交互,他考虑的更多是数据存取的问题,因此使用的协议相对DAS层面更高一些。光纤网络:对于存储来说,与以太网很大的一个不同就是他对带宽的要求非常高,因此SAN网络下,光纤成为了其连接的基础。而其上的光纤协议相比以太网协议而言,也被设计的更为简洁,性能也更高。光纤交换机:这个类似以太网,如果想要做到真正的“网络”,交换机是基础。
- 网络文件系统。存储空间可以共享,那文件也是可以共享的。NAS(Network attached storage)相对上面两个,看待问题的层面更高,NAS是在文件系统级别看待问题。因此他面的不再是存储空间,而是单个的文件。因此,当NAS和SAN、DAS放在一起时,很容易引起混淆。NAS从文件的层面考虑共享,因此NAS相关协议都是文件控制协议。NAS解决的是文件共享的问题;SAN(DAS)解决的是存储空间的问题。NAS要处理的对象是文件;SAN(DAS)要处理的是磁盘。为NAS服务的主机必须是一个完整的主机(有OS、有文件系统,而存储则不一定有,因为可以他后面又接了一个SAN网络),他考虑的是如何在各个主机直接高效的共享文件;为SAN提供服务的是存储设备(可以是个完整的主机,也可以是部分),它考虑的是数据怎么分布到不同磁盘。NAS使用的协议是控制文件的(即:对文件的读写等);SAN使用的协议是控制存储空间的(即:把多长的一串二进制写到某个地址)
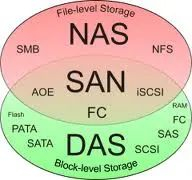
如图,对NAS、SAN、DAS的组成协议进行了划分,从这里也能很清晰的看出他们之间的差别。
NAS:涉及SMB协议、NFS协议,都是网络文件系统的协议。
SAN:有FC、iSCSI、AOE,都是网络数据传输协议。
DAS:有PATA、SATA、SAS等,主要是磁盘数据传输协议。
从DAS到SAN,在到NAS,在不同层面对存储方案进行的补充,也可以看到一种从低级到高级的发展趋势。而现在我们常看到一些分布式文件系统(如hadoop等)、数据库的sharding等,从存储的角度来说,则是在OS层面(应用)对数据进行存储。从这也能看到一种技术发展的趋势。
跑在以太网上的SAN
SAN网络并不是只能使用光纤和光纤协议,当初之所以使用FC,传输效率是一个很大的问题,但是以太网发展到今天被不断的完善、加强,带宽的问题也被不断的解决。因此,以太网上的SAN或许会成为一个趋势。
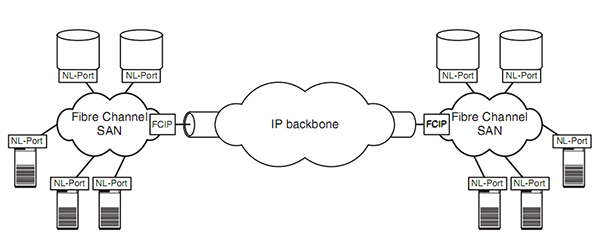
如图两个FC的SAN网络,通过FCIP实现了两个SAN网络数据在IP网络上的传输。这个时候SAN网络还是以FC协议为基础,还是使用光纤。
iFCP
通过iFCP方式,SAN网络由FC的SAN网络演变为IP SAN网络,整个SAN网络都基于了IP方式。但是主机和存储直接使用的还是FC协议。只是在接入SAN网络的时候通过iFCP进行了转换
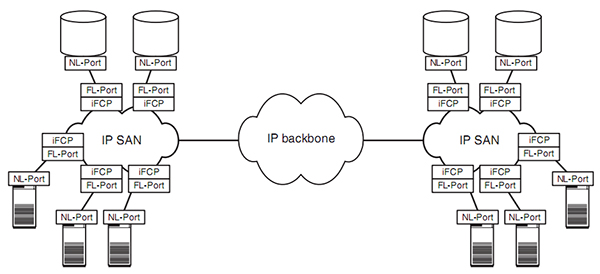
iSCSI
iSCSI是比较主流的IP SAN的提供方式,而且其效率也得到了认可。
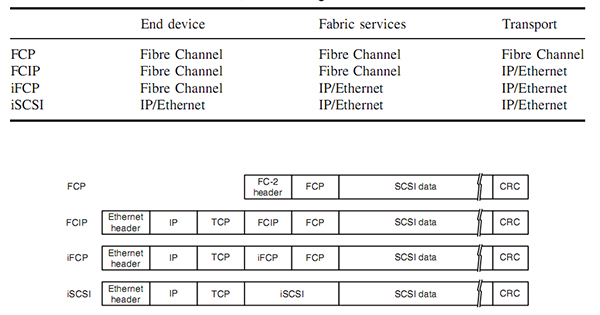
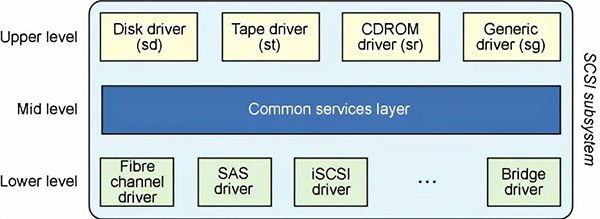
对于iSCSI,最重要的一点就是SCSI协议。SCSI(Small Computer Systems Interface)协议是计算机内部的一个通用协议。是一组标准集,它定义了与大量设备(主要是与存储相关的设备)通信所需的接口和协议。如图,SCSI为block device drivers之下。
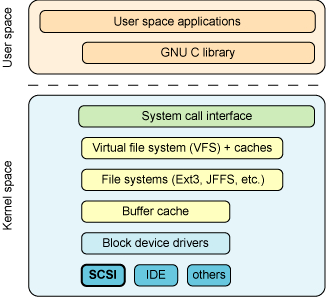
从SCIS的分层来看,共分三层:
高层:提供了与OS各种设备之间的接口,实现把OS如:Linux的VFS请求转换为SCSI请求
中间层:实现高层和底层之间的转换,类似一个协议网关。
底层:完成于具体物理设备之间的交互,实现真正的数据处理。