大家好,我是坤哥。
好久没更了,最近几周身体不好,得了比较严重的胃炎+心动过速症状,跑了好几趟医院,严重的时候心脏感觉很不舒服,胸闷气短,有濒死感,有时几乎整夜睡不好觉,在此奉劝大家还是要保重身体,千万不要做熬夜等伤身体的傻事,千万保重身体!
年前和年后我们完成了一次从 0 到 1 的上云之旅,其中踩了不少坑,也积累了不少宝贵的经验,所以在此总结成文,相信大家看了肯定有收获。
先说下此次上云的背景,创业后,我们的业务是从集团中独立出来了,不过系统还是和集团共用的,共用系统本来也不是个事儿,但由于集团早已今非昔比,核心人员都走得差不多了,导致一些核心系统不稳定,甚至出现过反向代理层宕机无人修复而导致整个交易跌零的严重事故,所以我们决定将系统完全从集团中剥离出来,由于之前集团系统上云采用的是腾讯云,所以我们也用了腾讯云,这样网络可以做到互通,共用一些待迁移的系统的镜像,也可以用腾讯云的工具对数据进行增量/全量迁移等以降低迁移成本。
云服务都有哪些
现在上云可以说是业界公认的趋势了,因为像阿里云,腾讯云等云厂商提供的工具真的太全了,基本上覆盖了一个大厂系统所需的方方面面,不信?我们不妨一起来看看,先来看下大厂的基本系统架构:
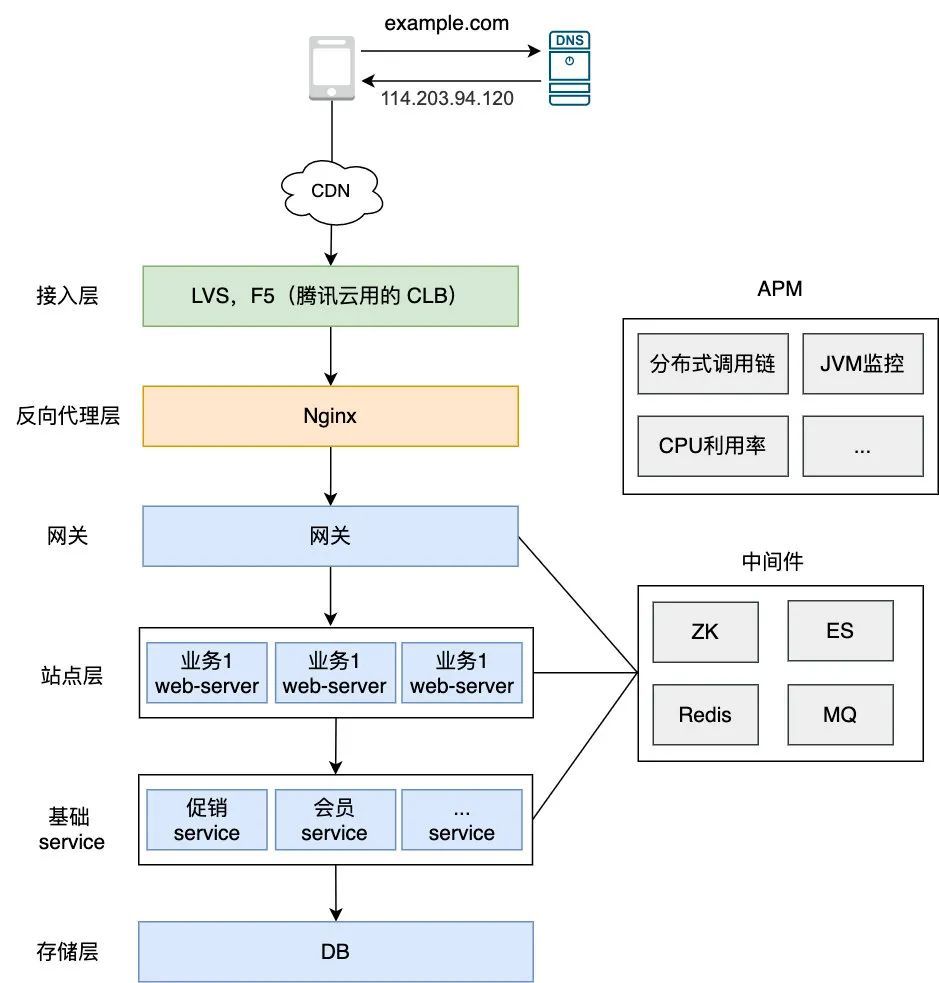 编辑搜图
编辑搜图
可以看到一个完整的可运行的系统需要提供:DNS 解析,CDN 服务,接入层,中间件,存储层,APM 等,云上这些工具全有 ,而且基本都是一键部署,这里简单举两个例子:
-
以部署 ZK 集群为例,如果你要部署一个 ZK 集群,那一般要在三台虚拟机上部署(ZK集群要求至少提供三台服务器),还需要编辑配置文件等,涉及到这种人为的工作往往比较容易繁琐,而且容易出错,但在腾讯云上点个按钮就可以自动帮你生成一个 ZK 集群,你所要做的只需在工程中替换此 ZK 集群地址,同时还可以查看它的基本信息(部署架构),数据管理,运行监控(JVM,连接数,内存使用率等),运行日志。
-
再比如你要部署一个 Redis 分片集群,一开始可能只需要一个分片,但后面随着业务的发展,需要进行分片扩容,那就比较麻烦了,一般需要用官方提供的 redis-trib 管理软件进行迁移,涉及到创建新的节点,将新的主节点加入集群,转移slot(重新分片),将从节点加入集群这些步骤,很烦琐,但如果用腾讯云本身提供的工具,只要选择对应的分片选项,再点确定,即可一键搞定(如下),非常方便,同样的,腾讯云也提供了 Redis 的缓存命中率,慢查询,CPU 使用率等监控。
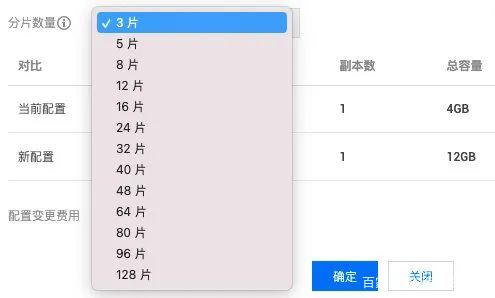 编辑搜图
编辑搜图
以上只是简单举了两个例子,事实上,像 MySQL,ES,MQ 等组件腾讯云上也基本都提供了一键式生成的操作,并且都附带了相关的监控与告警机制,极大地降低了运维成本,使用这些工具唯一的缺点就是:
 编辑搜图
编辑搜图
但我们也有一些控制成本的手段 ,比如:
-
如果项目是内网的话(如运营中心等),完全可以把这些项目都部署在同一台低配的虚拟机上以节省成本。
-
线上多个前端项目也可以同时部署在同一台机器上,配合 CDN 可以解决访问过慢的问题。
-
我们需要部署 APM(查看分布式调用链,JVM 监控等),就得在机器上部署 Skywalking 这样的分布式追踪框架以便采集数据,如果在每个服务的每台机器上都采集其实没有必要,成本也比较高,所以我们后来调整为了每个服务只有一台机器进行采集,并且降低了采样率,这样上传的数据就少很多,可以降低成本,采用这样的方式之后, skywalking 的采集数据成本只需要每天 10 元左右。
数据迁移
由于我们之前的系统是与集团共用的,现在要独立成一套,那就必须搞独立的配置中心,独立的 Redis,独立的 MQ,独立的数 DB......,所有的这一切都不是一蹴而就的,显然需要做到数据的平滑迁移,具体的操作如下:
-
数据库迁移:使用腾讯云上的数据迁移服务,进行全量+增量的升级,保证数据的一致性后再把数据源全部切成我们的库。
-
配置中心数据迁移:之前集团使用的 ZK 作为配置中心,所以我们直接使用了一款开源好用的迁移工具 zkcopy,执行以下命令即可完成 ZK 的数据迁移。
java -jar target/zkcopy.jar --source server:port/path --target server:port/path1.
Redis 迁移:另建一个 Redis 实例(只是 host 不同),使用 AOP 的形式让原 Redis(集团 Redis)在写入后新 Redis 也一起写入,这样维持一周左右,基本上就能把 Redis 的数据迁移完毕,伪代码如下:
@Slf4j
@Aspect
@Component
public class AopRedisReadWriteAspect {
@Resource
private RebateNewCacheClient rebateNewCacheClient; // 新 Redis 实例// RedisCacheClient 即集团 Redis 实例,使用 AOP 的方式可以让集团的 Redis 写入的同时也同步到我司的 Redis 实例来// 从而最终实现数据一致性
@Around(value = "execution(* com.xxx.RedisCacheClient.setex(" +
"String,int,String)) && args(key,expire,value)")
public Object setEx(ProceedingJoinPoint joinPoint, String key, int expire, String value) {
rebateNewCacheClient.setEx(key, expire, value);
return invokeOrigin(joinPoint);
}private Object invokeOrigin(ProceedingJoinPoint joinPoint) {
try {
return joinPoint.proceed();
} catch (Throwable throwable) {
// 打印日志 }
return null;
}}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.
-
MQ 迁移:首先 MQ 的创建和 ZK 集群等创建一样方便,我们要做的,只是确定好分区数等,确定好之后动动手指点击一下,这样就会一键生成一个高可用的 RocketMQ 集群,包括各种监控,消息状态查阅等也应有尽有,如果你自己部署估计要搞半天,在迁移的时候,我们做了两手准备,一是同时向集团和我司的 broker 发消息,然后灰度一部分用户,这部分用户只向我司的 broker 发消息,确认没问题后,再停掉发集团的 broker 逻辑,这样可以做到平稳过渡。
Ansible 简介
虽然云上有很多服务可以帮助我们快速接入 Redis 等中间件,快速迁移 DB 等数据,但除了这些基本上云服务可以提供的并不是说我们其他啥也不用干了,接下来我们来谈下本文的重点:项目部署的架构设计。比如一个 Java 项目,你要跑起来,总得先编译打包(生成 jar 包)吧,打包之后发布总不能立马中断正在运行的服务吧,你得用优雅停机的方式来停掉服务然后再部署新包,部署之后如果发现有问题要回滚吧,这些步骤如果用手工操作肯定不现实,最好的方式其实是写成脚本的方式然后一键部署,不过一个服务可能有多台机器,难道我们需要一台台登录然后再手动触发相应的部署脚本?显然不现实,更合理的方式是首先要把所有的这些部署步骤写成脚本的形式,然后再用一个支持批量部署的自动化运维工具来部署,经过调研,我们选择了 Ansible。
什么是 Ansbile ,它有什么优势?
Ansible是一款简单的运维自动化工具,只需要使用ssh协议连接就可以实现批量系统配置、批量程序部署、批量运行命令等功能。
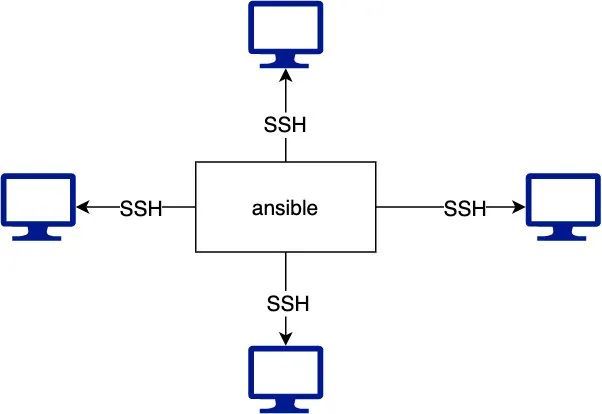 编辑搜图
编辑搜图
ansbile 有以下几个优势:
-
它是通过 SSH 来接管对应机器的控制权的,对应的机器无需安装任何的 ansible 客户端,也无需启用额外的服务,所以即便 ansible 升级也不影响对应的机器;
-
有大量常规运维操作模块,可实现日常绝大部分操作;
-
配置简单、功能强大、扩展性强;
-
通过 Playbooks(剧本) 来定制强大的配置、状态管理,所谓剧本,即 YAML 格式文件,多个任务定义在此文件中,定义主机需要用哪些模块(主要有核心模块和自定义模块)来完成这些功能。
由于它的上述这些特点,Ansible 很快流行了起来,甚至可以说是运维必备的一款神器了,上图是 Ansible 的极简版,我们再稍微展开一下它的架构看看:
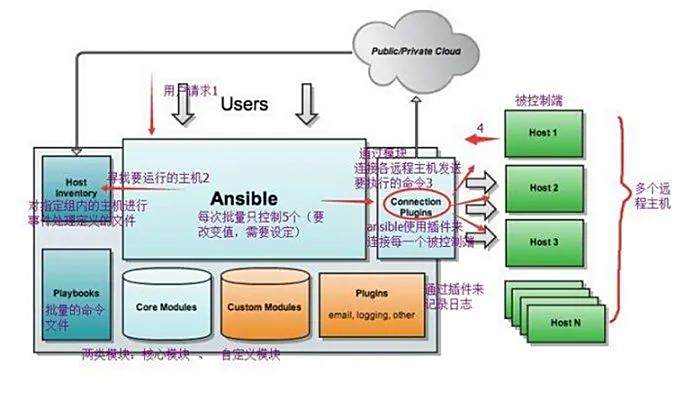 编辑搜图
编辑搜图
它的执行流程如下:
-
用户登录(一般通过跳板机) ansible 所在机器。
-
通过 Host Inventory 来指定要控制的主机,这个一般是个 yaml 文件,我们可以在此文件中指定所有我们可以控制的 host,另外一个服务通常有多台机器,我们也可以指定哪些机器属于某个服务,这里简单举个例子:
all: hosts: 10.100.1.2: 10.100.1.4: 10.100.1.5: children: build: hosts: 10.100.1.2: operation_center: hosts: 10.100.1.4: 10.100.1.5:1.2.3.4.5.6.7.8.9.10.11.12.13.
上图中, 10.100.1.4,10.100.1.5即属于同一个服务operator_center,如果我们到时要发布这个服务的话,只需要指定其服务名 operator_center 即可(下文会介绍)。
-
通过步骤 2 我们即可指定需要操控哪些机器,然后 ansible 再通过连接模块(即 Connection Plugins,采用 SSH 连接)连接步骤 2 中指定的 host 然后利用核心模块(core modules)写好相应的 Playbooks 并执行。
ansible 的 core modules(核心模块)有很多,功能也很强大,基本不需要自定义模块,像我们这次上云也只用了核心模块,来看几个比较常见的模块:
-
shell模块:可以在远程主机上调用 shell 解释器运行命令,支持 shell 的各种功能,例如管道等。
-
copy 模块:将文件复制到远程主机,同时支持给定内容生成文件和修改权限等。
-
file 模块:设置文件的属性,比如创建文件、创建链接文件、删除文件等。
-
fetch模块:从远程某主机获取(复制)文件到本地(即 ansible 所在机器)。
-
command 模块:在远程主机上执行命令,并将结果返回到调用机上(也就是 ansible 所在主机)。
-
cron 模块:定时任务模块,这个大家应该比较熟悉了。
我们知道一般工程都需要构建(或者说打包,两个概念相差不大)之后才能部署,比如 Java 工程要打包成 Jar 文件然后再部署(执行 Jar 包),前端工程也需要打包后才能部署(比如把多个 js 文件合并成一个以减少请求提升性能,再比如你可能使用 SCSS 或 less 来写 CSS,也需要编译成 CSS 文件,并且合并起来),那么问题来了,能否直接在生产机器上执行打包操作呢?答案显然是否定的,主要有两个原因:
-
打包由于采用了各种优化手段(比如并行打包等)是很耗费 CPU 的,如果在生产上正在对外服务的机器上执行打包操作的话,那么很可能由于打包时耗费的 CPU 过大而导致当前正在执行的机器出现响应太慢,拒绝请求等问题,这显然是不可接受的。
-
服务是以集群的形式存在的,可能一个服务有好几台机器,这些机器部署其实所需的 jar 包完全是一样的,没有必要在各个机器上都执行一遍通过的打包操作。
部署架构设计
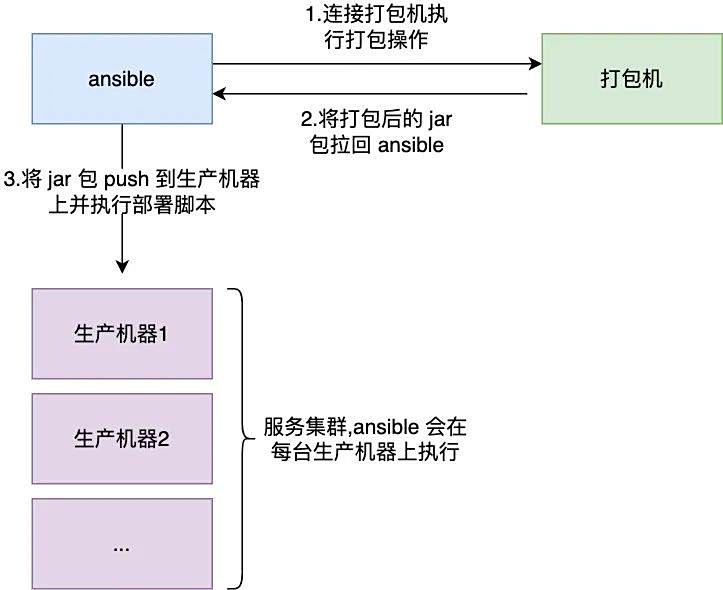
综上,我们需要一个专门的打包机,将打包的工作交给打包机,打包机打包好之后,我们再把相应的包发到生产的机器上,然后再执行部署脚本,架构模型如下:
 编辑搜图
编辑搜图
通过这样的方式,打包机承担了所有繁重的活,打包之后,ansible 会通过 fetch 模块将这些 jar 包拉到本地,然后再通过 push 模块把 jar 包 push 到服务集群上的所有机器,然后再执行比较轻量级的部署脚本。
介绍了这么多 Ansible 相关的概念,大家可能还是一脸懵逼,那么接下来我们一起来看下如何利用 Ansible 来执行我们所设计的打包部署步骤,这样大家对 Ansible 的功能也能有更全面的认识。
样例脚本我们一一介绍下:有三个文件
1.production-hosts.yaml 文件:即我们上文提到的的 host inventory;
#production-hosts.yaml all: hosts: 10.100.1.2: 10.100.1.4: 10.100.1.5: children: build: # 打包机 hosts: 10.100.1.2: operation_center: # operation_center 服务 hosts: 10.100.1.4: 10.100.1.5:1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
2.打包 playbook: java-build.yaml;
# java-build.yaml- name: build project artifact hosts: build // build 表示打包机,定义在 production-hosts.yaml 文件中 tasks: - name: Pull source code and checkout branch ansible.builtin.git: repo: '工程git地址' dest: workspace/operation_center version: master force: yes - name: Grant execute permission to build.sh ansible.builtin.file: // file 模块 path: workspace/operation_center/build.sh mode: '0755' - name: Build project // 执行打包脚本 ansible.builtin.shell: ./build.sh // shell 模块 args: chdir: workspace/operation_center executable: /bin/bash - name: Create archive project // 打包后会生成 jar 包,创建目录存放存放即将压缩后的 jar 包 ansible.builtin.file: path: archive/operation_center state: directory args: chdir: /home/buser - name: Archive latest artifact // 压缩 jar 包到上一步创建的目录中 ansible.builtin.shell: cp workspace/operation_center/target/operation_center.jar archive/operation_center/latest.jar args: chdir: /home/buser - name: Fetch project artifact to local // 使用 fetch 模块将上一步压缩的 jar 包从打包机拉到 ansible 所在机器上 ansible.builtin.fetch: src: archive/operation_center/latest.jar dest: /tmp/operation_center/ flat: yes - name: Fetch bin file to local // 将部署脚本从打包机拉到本地,准备传给线上机器执行部署操作 ansible.builtin.fetch: src: /home/buser/workspace/operation_center/deploy.sh dest: /tmp/operation_center/ flat: yes1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.
3.部署 playbook: java-deploy.yaml;
# java-deploy.yaml- name: Deploy project hosts: operation_center # 表示线上服务器,定义在 production-hosts.yaml 文件中 serial: 1 any_errors_fatal: true # 只要一步失败,部署流程即终止 tasks: - name: Upload artifact & restart project block: - name: Push project artifact to remote # 将 ansbile 上的 jar 包 push 到服务器上 ansible.builtin.copy: src: /tmp/operation_center/latest.jar dest: /opt/apps/business/operation_center.jar - name: Push deploy file to remote # 将 ansbile 上的部署脚本 push 到服务器上 ansible.builtin.copy: src: /tmp/operation_center/deploy.sh dest: /opt/apps/bin/ - name: Start operation_center ansible.builtin.shell: bash bin/start.sh # 执行部署脚本 args: chdir: /opt/apps executable: /bin/bash environment: appEnv: prod - name: Health check 8001 # 健康检查 uri: url: http://127.0.0.1:8001/service/health/deepCheck return_content: yes status_code: -1 register: this failed_when: "'health' not in this.content" when: health_check == "8001" - name: Health check 8081 uri: url: http://127.0.0.1:8081/health/check return_content: yes register: this failed_when: "'health' not in this.content" when: health_check == "8081" become: yes # 在线上服务器上以 root 身份执行上述的部署步骤 become_user: root1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.
有了以上三个文件,只要分别执行打包和部署操作 playbook 即可,如下:
ansible-playbook -i production-hosts.yaml java-build.yaml # 在打包机中打包 ansible-playbook -i production-hosts.yaml java-deploy.yaml # 在线上服务器上部署1.2.
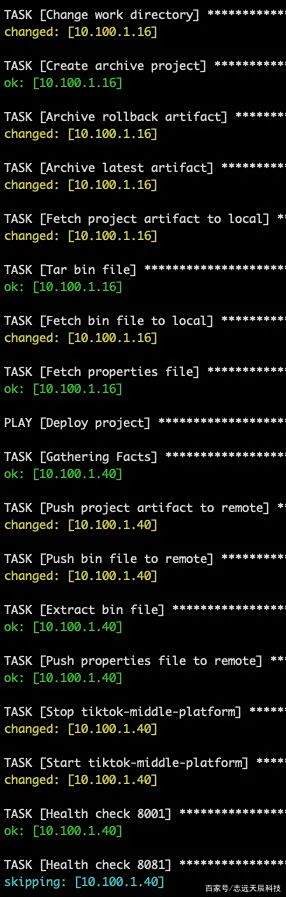
可以看到只要使用 ansible 的核心模块即可完成我们的打包部署需求,执行流程会通过上文中的 name 展示,部署流程部分展示如下:
 编辑搜图
编辑搜图
可以看到整个流程部署流程非常的清晰!
为了方便起见,以上脚本只是简单介绍了一下打包部署的部分步骤,其实我们还需考虑回滚等操作,由于不是本文的重点,所以这里就不再做介绍了。
聊点题外话
现在各个云厂商提供的工具确实相当广泛,而且很好用了,基本每个开发都能承担 devops(开发运维) 的工作,于是就有了一个担忧:开发的工作到时会不会被替换,尤其是运维就更有这样的忧虑了,之前就有一位运维哥们说这些云厂商工具这么好用,很担心自己的饭碗被抢了,也确实,毕竟基本上你能想到的运维工作它都能一键点击帮你做了,甚至"侵蚀"到数据库,中间件这些领域,曾经一个数据库团队的 Leader 反对上云,说了一大堆上云的缺点,但他自己私下其实也说了,上云的趋势已经不可阻挡了,很担心有一天会失业 。
之前有一位读者提到下面这样的问题:

我的回答是像这些其实云厂商都提供了很成熟的解决方案,基本一键生成,于是就有了这位读者的灵魂拷问。

我相信很多人也有这有这样的疑问,我的看法是云服务厂商这些提供的只是工具,但如何利用好这些工具,还需要我们来操控,所以我给的建议如下:

开发如果想向更高阶发展,还是要掌握扎实的理论基础与实战经验