如何使用自建Hadoop访问全托管服务化HDFS(OSS-HDFS服务)
1. 服务介绍
OSS-HDFS服务(JindoFS 服务)是一款云原生数据湖3.0存储产品,根据一致的元数据办理才能,在彻底兼容 HDFS 文件体系接口的一起,供给充沛的 POSIX 才能支撑,能更好的满意大数据和 AI 范畴丰厚多样的数据湖核算场景。
经过OSS-HDFS服务,无需对现有的 Hadoop/Spark 大数据剖析运用做任何修正,经过简略的装备就能够像在原生HDFS中那样办理和拜访数据,一起取得OSS无限容量、弹性扩展、更高的安全性、可靠性和可用性支撑。

数据湖HDFS演进途径
1.1 主要特性
1.1.1 HDFS 兼容拜访
OSS-HDFS服务(JindoFS服务)彻底兼容HDFS接口,一起支撑目录层级的操作,用户只需集成JindoSDK,即可为Apache Hadoop的核算剖析运用(例如MapReduce、Hive、Spark、Flink等)供给了拜访HDFS服务的才能,像运用 Hadoop 分布式文件体系 (HDFS) 相同办理和拜访数据,运用概况请参阅OSS-HDFS服务快速入门;
1.1.2 POSIX 才能支撑
OSS-HDFS服务能够经过JindoFuse供给POSIX支撑。能够把OSS-HDFS服务上的文件挂载到本地文件体系中,能够像操作本地文件体系相同操作JindoFS服务中的文件,运用概况请参阅运用JindoFuse拜访OSS-HDFS服务
1.1.3 高性能、高弹性、低本钱
运用自建Haddop集群,严峻依赖硬件资源,很难做到资源的弹性弹性,本钱和效益上捉襟见肘,比如规划超越数百台,文件数到达4亿左右时NameNode根本到达瓶颈。跟着元数据规划的上涨,其QPS存在下降的趋势。而OSS-HDFS服务是专为多租户、海量数据存储服务设计,元数据办理才能可弹性扩容,可支撑更高的并发度、吞吐量和低时延,即使超越10亿文件数仍然能够坚持服务稳定,供给高性能、高可用的服务。一起采用一致元数据办理才能,可轻松应对超大文件规划,并支撑多种分层分级战略,体系的资源利用率更高,更节约本钱,能充沛满意事务体量快速改变的需求。
1.1.4 数据持久性和服务可用性
OSS-HDFS服务中数据存储在方针存储OSS上,而OSS作为阿里巴巴全集团数据存储的中心基础设施,多年支撑双11事务顶峰,历经高可用与高可靠的苛刻检测。
-
服务可用性不低于99.995%。
-
数据设计持久性不低于99.9999999999%(12个9)。
-
规划自动扩展,不影响对外服务。
-
数据自动多重冗余备份。
1.2 典型适用场景
OSS-HDFS 服务供给全面的大数据和 AI 生态支撑,典型场景如下概述,相关文档请参阅链接:阿里云 OSS-HDFS 服务(JindoFS 服务) 用户文档。
1.2.1 Hive/Spark 离线数仓
OSS-HDFS服务原生支撑文件/目录语义和操作,支撑毫秒级和原子性目录 rename,在才能上对齐 HDFS,擅长和合适用于开源 Hive/Spark 离线数仓。
1.2.2 OLAP
OSS-HDFS服务供给 append、truncate、flush、pwrite 等基础文件操作,经过 JindoFuse 充沛支撑 POSIX,能够为 ClickHouse 这类 OLAP 场景替换本地磁盘做存/算别离计划,再借助于缓存体系进行加快,到达最佳性价比。
1.2.3 AI 练习/推理
OSS-HDFS服务供给 append、truncate、flush、pwrite 等基础文件操作,经过 JindoFuse 充沛支撑 POSIX,无缝对接 AI 生态和已有的 Python 练习/推理程序。
1.2.4 HBase 存/算别离
OSS-HDFS服务原生支撑文件/目录语义和操作,支撑 flush 操作,在才能上对齐 HDFS,能够用于代替 HDFS 做 HBase 存/算别离计划。相较于 HBase + OSS(规范 bucket)计划,HBase + OSS-HDFS服务计划不依赖 HDFS 来寄存 WAL 日志,大幅简化整体计划架构。
1.2.5 实时核算
OSS-HDFS服务高效支撑 flush 和 truncate 操作,能够用来无缝代替 HDFS 在 Flink 实时核算运用场景下做 sink/checkpoint 存储。
1.2.6 数据迁移
OSS-HDFS 服务作为新一代云原生数据湖存储,支撑 IDC HDFS 平迁上云,确保和优化 HDFS 运用体会,一起享用弹性弹性、按需付费的本钱效益,大幅优化存储本钱。JindoDistCp 东西供给高效方法支撑将 HDFS 文件数据(包括文件特点等元数据)无缝迁入 OSS-HDFS 服务,并根据 HDFS Checksum 支撑供给快速比对。
OSS-HDFS 服务作为 JindoFS Block 方式的服务化晋级版本,供给晋级计划,支撑将 EMR 集群内的 JindoFS Block 方式文件元数据(寄存于 header 节点上的本地 RocksDB)快速迁入 OSS-HDFS 服务 bucket,坚持 OSS 上已有的 JindoFS 文件数据块不变(无须转换、迁移)。
OSS-HDFS 服务也行将支撑 OSS 现有 bucket 数据快速导入,便利 OSS 用户体会运用新服务的功用和特性。
1.3 服务特性支撑状况
|
场景特性 |
支撑状况 |
|
|
Hive/Spark 数仓 |
原生支撑文件/目录语义和操作 |
✓ |
|
支撑文件/目录权限 |
✓ |
|
|
支撑目录原子性/毫秒级 rename |
✓ |
|
|
支撑 setTimes 设置时刻 |
✓ |
|
|
扩展特点(XAttrs)支撑 |
✓ |
|
|
ACL支撑 |
✓ |
|
|
本地读缓存加快 |
✓ |
|
|
Kerberos + Ranger 认证鉴权计划 |
行将支撑 |
|
|
分层存储和归档 |
行将支撑 |
|
|
操作审计(audit log) |
行将支撑 |
|
|
元数据(fsimage)剖析 |
行将支撑 |
|
|
OSS 数据快速导入 |
行将支撑 |
|
|
HDFS 代替 |
快照(Snapshot)支撑 |
✓ |
|
支撑文件 flush/sync |
✓ |
|
|
支撑文件截断 truncate |
✓ |
|
|
支撑文件 append |
✓ |
|
|
Checksum 支撑 |
✓ |
|
|
HDFS 回收站自动清理 |
✓ |
|
|
HDFS 数据加密 |
行将支撑 |
|
|
POSIX 才能 |
文件随机写支撑 |
✓ |
|
truncate/append 支撑 |
✓ |
|
|
flush 支撑 |
✓ |
|
|
fallocate |
行将支撑 |
|
|
flock |
行将支撑 |
|
2. 运用过程
2.1 创立内网拜访OSS-HDFS服务的VPC 环境
2.1.1 创立VPC环境
登陆阿里云官网,点击“产品与服务”中的“专有网络VPC”

切换到与行将运用的OSS-HDFS 服务Bucket相同的地域后,点击“创立专有网络” 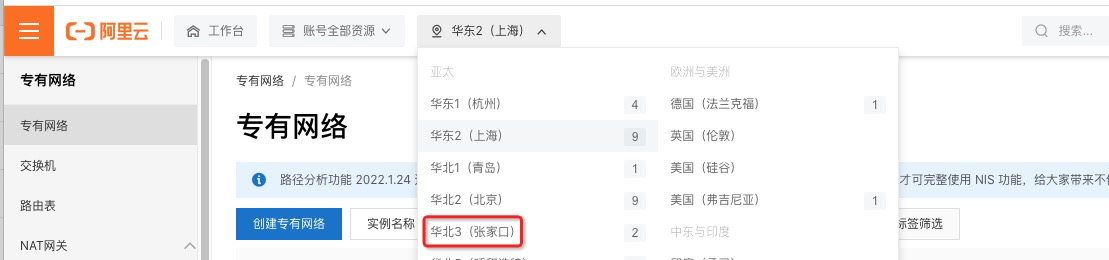
填入必要信息后点击“确认” 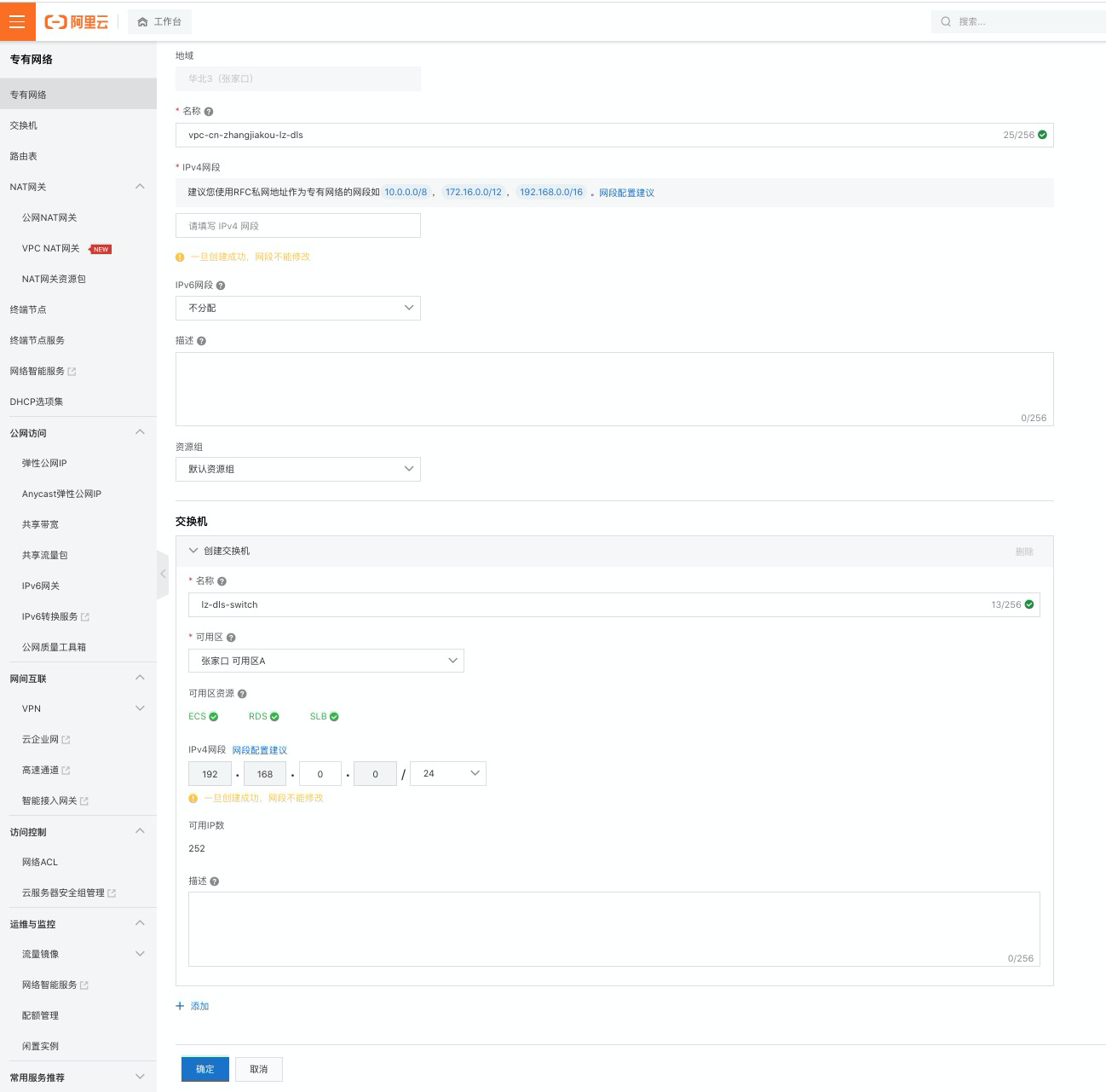
2.1.2 创立云服务器(ECS)
进入新建的vpc办理页面,切换到“资源办理” ,增加云服务器(ECS) 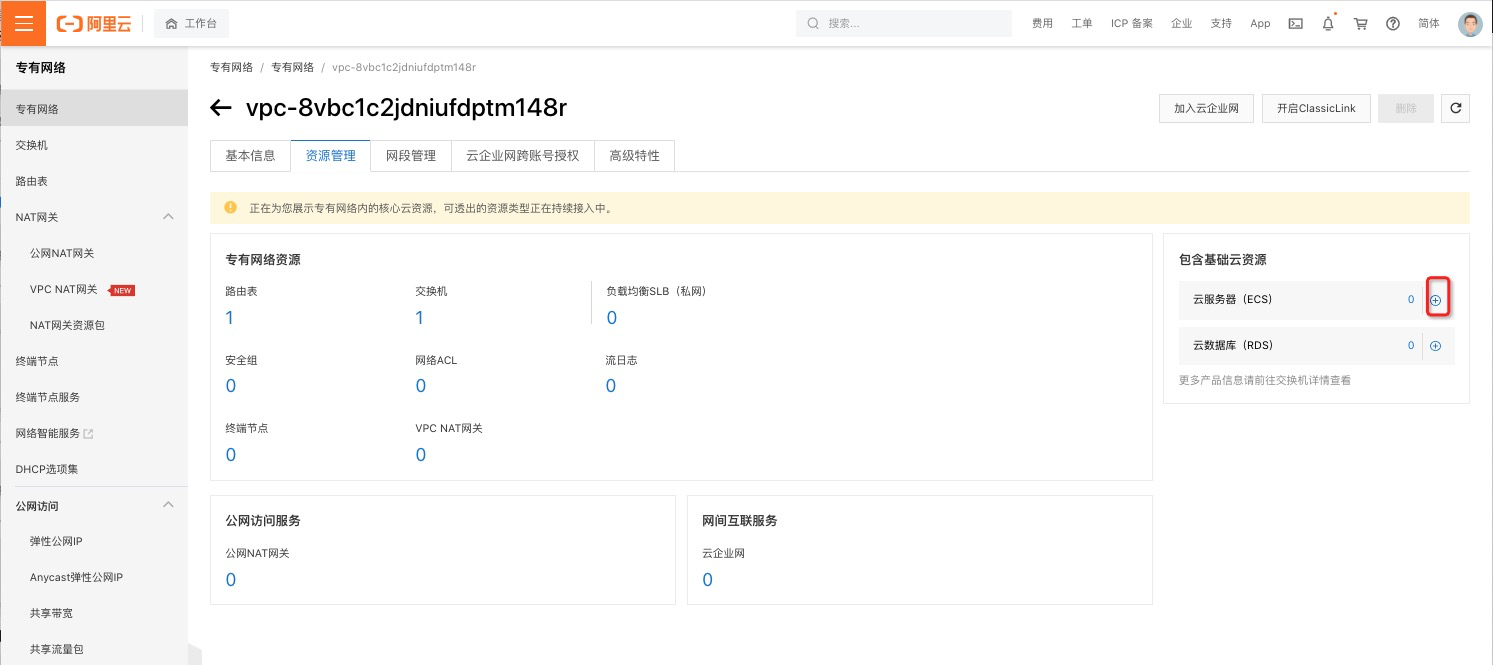
在翻开的页面中点击“创立实例” 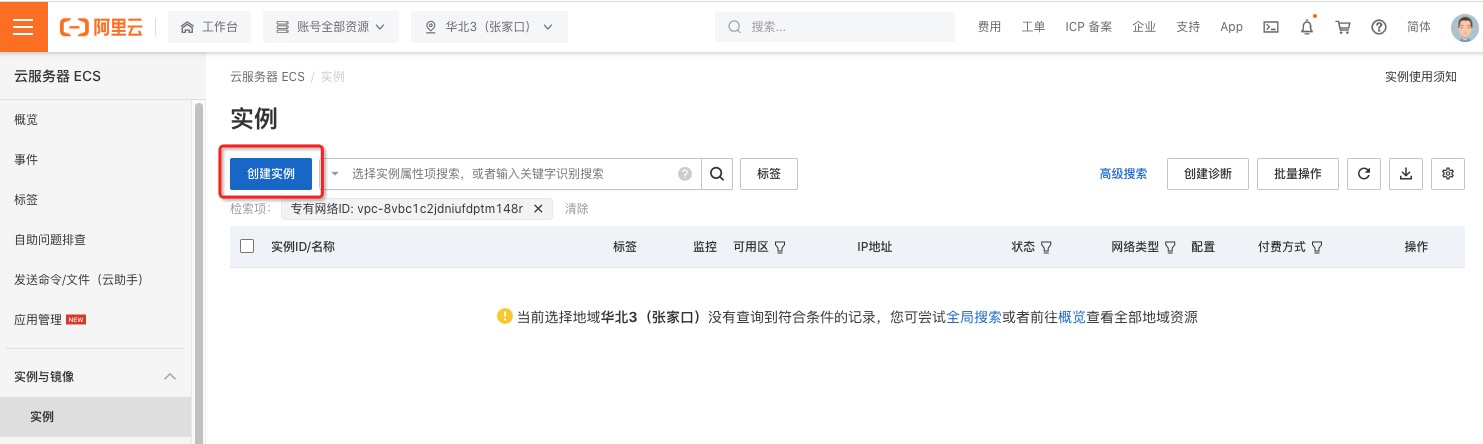
根据需求填写装备等侯提交确认 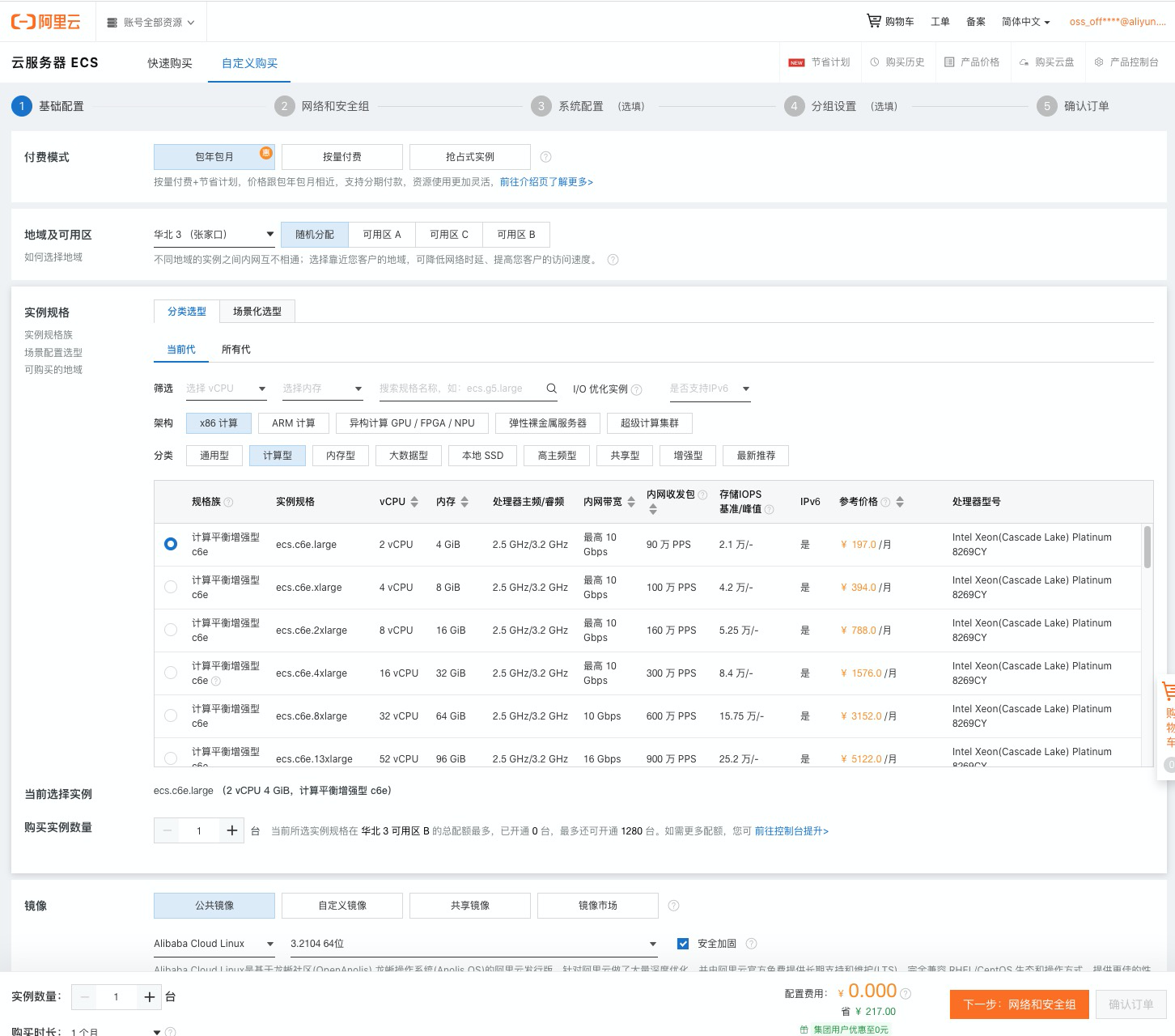
如需求拜访外网,请挑选分配工网IP 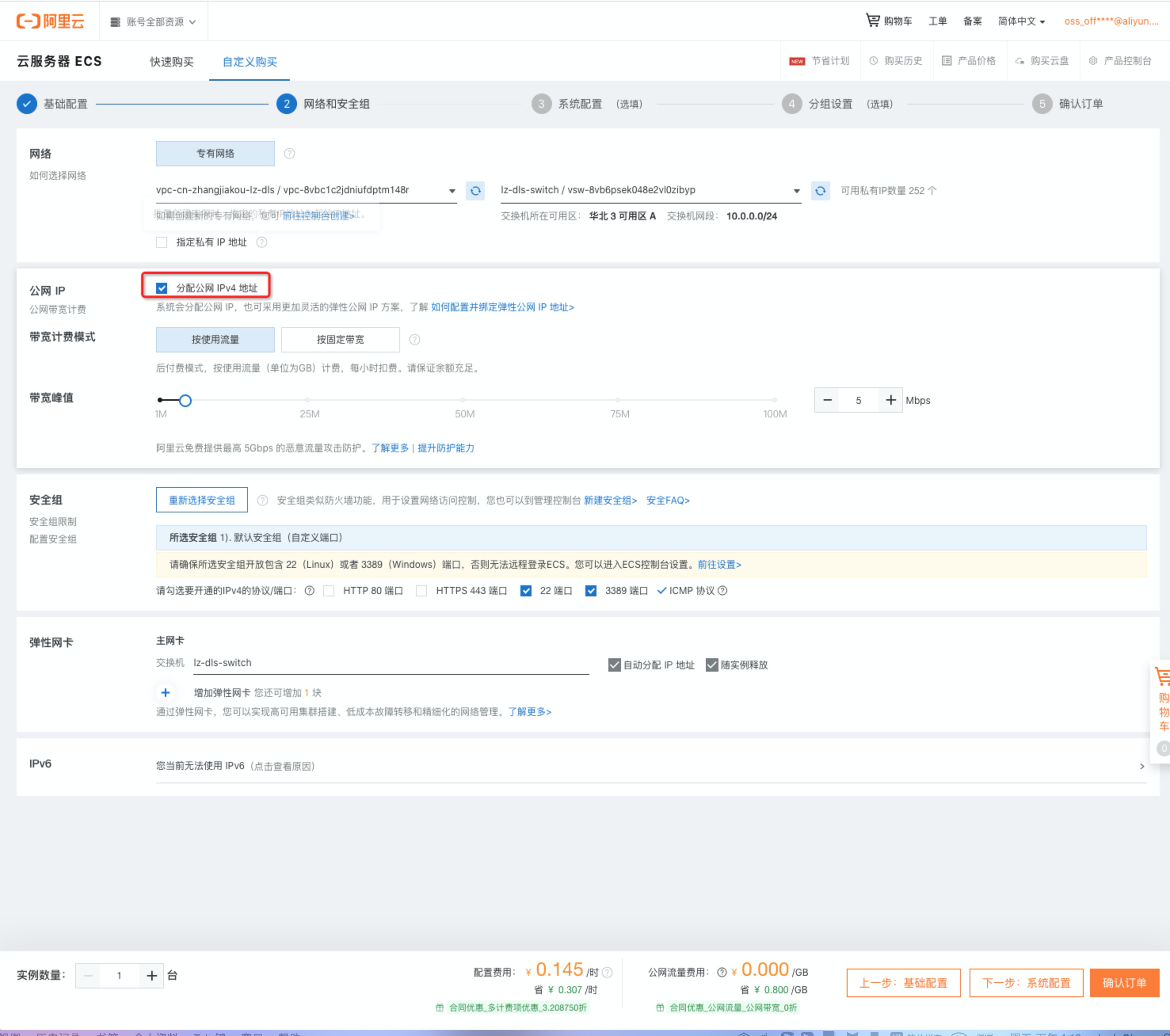
2.2 创立Hadoop运转环境
2.2.1 装置Java 环境
ECS创立完结后进入该实例控制台点击远程衔接,进入体系 
装置JDK并装备环境变量,JDK版本不低于1.8
#卸载已有jdk rpm -qa | grep java | xargs rpm -e --nodeps #装置java yum install java-1.8.0-openjdk* -y # 装备环境变量 ## 暂时收效直接export; ## 当时用户收效更新到 ~/.bashrc; ## 所有用户收效更新到/etc/profile 使装备收效; 修改完. /etc/profile使其收效 vim /etc/profile # 增加环境变量, 假如提示当时jdk path不存在则到/usr/lib/jvm/ 寻觅,java-1.8.0-openjdk export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar export PATH=$PATH:$JAVA_HOME/bin
2.2.2 装置SSH
# 装置 yum install -y openssh-clients openssh-server # 启用服务 systemctl enable sshd && systemctl start sshd
生成 SSH 密钥,并将生成的密钥增加到信赖列表:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
2.2.3 装置Hadoop
# 下载 wget https://mirrors.sonic.net/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz # 解压 tar xzf hadoop-3.3.1.tar.gz # 移动到常用位置 mv hadoop-3.3.1 /usr/local/hadoop
装备环境变量
# 暂时收效直接export; # 当时用户收效更新到 ~/.bashrc; # 所有用户收效更新到/etc/profile 使装备收效; 修改完. /etc/profile使其收效 vim /etc/profile # 设置hadoop环境变量 export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$PATH # 更新hadoop装备文件中JAVA_HOME cd $HADOOP_HOME vim etc/hadoop/hadoop-env.sh # 将JAVA_HOME由本来${JAVA_HOME}换成具体途径,这样在集群环境中才不会出现问题 export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64
更新装备文件
更新两个文件:core-site.xml 和 hdfs-site.xml
#假如提示目录不存在,则履行. /etc/profile,使环境变量收效 cd $HADOOP_HOME/etc/hadoop
更新core-site.xml ,增加特点
<configuration> <property> <name>fs.defaultFSname> <value>hdfs://localhost:9000value> property>
<property> <name>hadoop.tmp.dirname> <value>/opt/module/hadoop-2.6.5/data/tmpvalue> property> configuration>
更新 hdfs-site.xml,增加特点:
<configuration> <property> <name>dfs.replicationname> <value>1value> property> configuration>
格局化文件结构
hdfs namenode -format
发动HDFS
然后发动 HDFS, 发动分三个过程,分别发动 NameNode、DataNode 和 Secondary NameNode。
cd /usr/local/hadoop/ # 发动 sbin/start-dfs.sh # 检查进程 jps
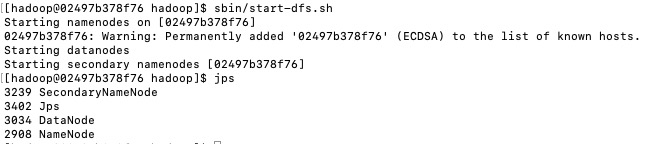
到此为止,HDFS 看护进程现已建立,因为 HDFS 本身具备 HTTP 面板,咱们能够经过浏览器拜访http://172.17.0.4:9870/来检查 HDFS 面板以及详细信息:
2.2.4 Hadoop测验
履行hadoop version指令,如能正常返回version信息表示装置成功

运转一个hadoop 官方示例 - 单词次数核算
# /hello 为输入目录; /hi 为输出目录,必须不存在 hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /hello /hi
2.2.5 HDFS 测验
|
指令 |
适用范围 |
|
hadoop fs |
运用范围最广,方针:可任何方针 |
|
hadoop dfs |
只HDFS文件体系相关 |
|
hdfs fs |
只HDFS文件体系相关(包括与Local FS间的操作),现已Deprecated |
|
hdfs dfs |
只HDFS文件体系相关,常用 |
示例
# 显示根目录 / 下的文件和子目录,绝对途径 hadoop fs -ls -R / # 新建文件夹,绝对途径 hadoop fs -mkdir /hello # 上传文件 hadoop fs -put hello.txt /hello/ # 下载文件 hadoop fs -get /hello/hello.txt # 输出文件内容 hadoop fs -cat /hello/hello.txt
2.3 切换本地HDFS到云上OSS-HDFS服务
2.3.1 创立OSS Bucket并注册HDFS服务
-
联络技术支撑请求试用,运用留意:
-
目前支撑华东1(杭州)、华东2(上海)、华南1(深圳)和华北2(北京)地域支撑敞开HDFS服务。
-
HDFS服务敞开后不支撑关闭,请慎重操作。
-
归档以及冷归档存储类型Bucket不支撑敞开HDFS服务。
-
登录OSS办理控制台。
-
单击Bucket列表,然后单击创立Bucket。
-
在创立Bucket面板中,切换到支撑HDFS服务地域,挑选注册HDFS服务
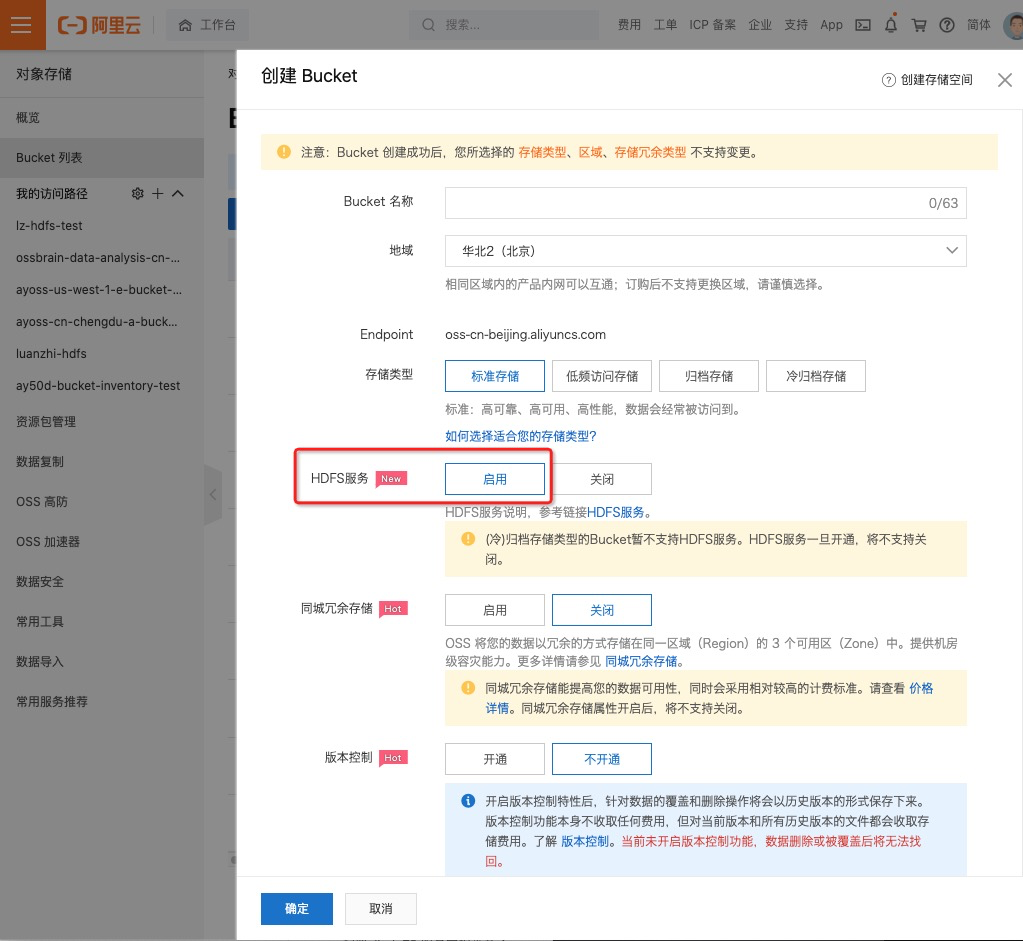
-
单击确认。
2.3.2 授权拜访
-
授权服务端办理已注册HDFS服务的Bucket。首次运用HDFS功用时,需求先在RAM控制台完结以下授权,以便OSS服务账号能够办理Bucket中的数据。
-
创立名为AliyunOSSDlsDefaultRole的人物。
-
登录RAM控制台。
-
在左边导航栏,挑选身份办理 > 人物。
-
单击创立人物,挑选可信实体类型为阿里云服务,单击下一步。
-
人物类型挑选一般服务人物,人物称号填写为AliyunOSSDlsDefaultRole,挑选受信服务为方针存储。
-
单击完结。人物创立完结后,单击关闭。
-
-
新建名为AliyunOSSDlsRolePolicy的自定义权限战略。
-
在左边导航栏,挑选权限办理 > 权限战略。
-
单击创立权限战略。
-
在新建自定义权限战略页面,填写战略称号为AliyunOSSDlsRolePolicy,装备方式挑选脚本装备,并在战略内容中填写以下权限战略。
-
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": "oss:ListObjects",
"Resource": [
"acs:oss:*:*:*" ]
},
{
"Effect": "Allow",
"Action": "oss:*",
"Resource": [
"acs:oss:*:*:*/.dlsdata",
"acs:oss:*:*:*/.dlsdata*" ]
}
]
}
-
单击确认。
-
为人物颁发自定义权限战略。
-
在左边导航栏,挑选身份办理 > 人物。
-
单击RAM人物AliyunOSSDlsDefaultRole右侧的准确授权。
-
在增加权限页面,挑选权限类型为自定义战略,输入已创立的自定义权限战略称号AliyunOSSDlsRolePolicy。
-
单击确认。
-
-
授权RAM用户拜访已注册HDFS服务的Bucket。假如您运用服务人物(例如EMR服务人物AliyunEMRDefaultRole)拜访已注册HDFS服务的Bucket,请拜见上述为RAM用户授权的过程完结服务人物授权。
-
创立RAM用户。具体操作,请拜见创立RAM用户。
-
创立自定义战略,战略内容如下:
{
"Statement": [
{
"Effect": "Allow",
"Action": "oss:*",
"Resource": [
"acs:oss:*:*:*/.dlsdata",
"acs:oss:*:*:*/.dlsdata*" ]
},
{
"Effect": "Allow",
"Action": [
"oss:GetBucketInfo",
"oss:PostDataLakeStorageFileOperation" ],
"Resource": "*" }
],
"Version": "1" }
创立自定义战略的具体操作,请拜见创立自定义权限战略。
-
为RAM用户授权已创立的自定义战略。具体过程,请拜见为RAM用户授权。
2.3.3 下载JindoSDK并装备
下载最新的 tar.gz 包 jindosdk-x.x.x.tar.gz (下载页面)。
# 切换到方针目录 cd /usr/lib/ # 下载jdk 包 wget https://jindodata-binary.oss-cn-shanghai.aliyuncs.com/release/4.1.0/jindosdk-4.1.0.tar.gz # 解压 tar xzf jindosdk-4.1.0.tar.gz
装备环境变量
# 切换到方针目录 vim /etc/profile # 文件结尾增加装备后保存 export JINDOSDK_HOME=/usr/lib/jindosdk-4.1.0 export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:${JINDOSDK_HOME}/lib/* # 使装备收效 . /etc/profile
装备 OSS-HDFS 服务实现类及 Access Key,根本装备方法如下,除此之外JindoSDK还支撑更多的 AccessKey 的装备方法,概况参阅 JindoSDK Credential Provider 装备。
cd $HADOOP_HOME/etc/hadoop
将 JindoSDK OSS 实现类装备到 Hadoop 的core-site.xml中。
<configuration> <property> <name>fs.AbstractFileSystem.oss.implname> <value>com.aliyun.jindodata.oss.JindoOSSvalue> property> <property> <name>fs.oss.implname> <value>com.aliyun.jindodata.oss.JindoOssFileSystemvalue> property> configuration>
将已敞开 HDFS 服务的 Bucket 对应的Access Key ID、Access Key Secret等预先装备在 Hadoop 的core-site.xml中。
<configuration> <property> <name>fs.oss.accessKeyIdname> <value>xxxxvalue> property> <property> <name>fs.oss.accessKeySecretname> <value>xxxxvalue> property> configuration>
2.3.4 装备 OSS-HDFS 服务 Endpoint
拜访 OSS Bucket 上 OSS-HDFS服务需求装备 Endpoint(cn-xxx.oss-dls.aliyuncs.com),与 OSS 方针接口的 Endpoint(oss-cn-xxx.aliyuncs.com)不同。JindoSDK 会根据装备的 Endpoint 拜访 JindoFS 服务 或 OSS 方针接口。
运用 JindoFS 服务时,推荐拜访途径格局为:
oss://./
如: oss://dls-chenshi-test.cn-shanghai.oss-dls.aliyuncs.com/Test。
这种方法在拜访途径中包括 OSS-HDFS 服务的 Endpoint,JindoSDK 会根据途径中的 Endpoint 拜访对应的 OSS-HDFS 服务接口。 JindoSDK 还支撑更多的 Endpoint 装备方法,概况参阅JindoFS 服务 Endpoint 装备。
2.3.5 开始运用
新建目录
在JindoFS服务上创立目录 用例: hdfs dfs -mkdir oss://./Test/subdir
hdfs dfs -mkdir oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/Test

新建文件
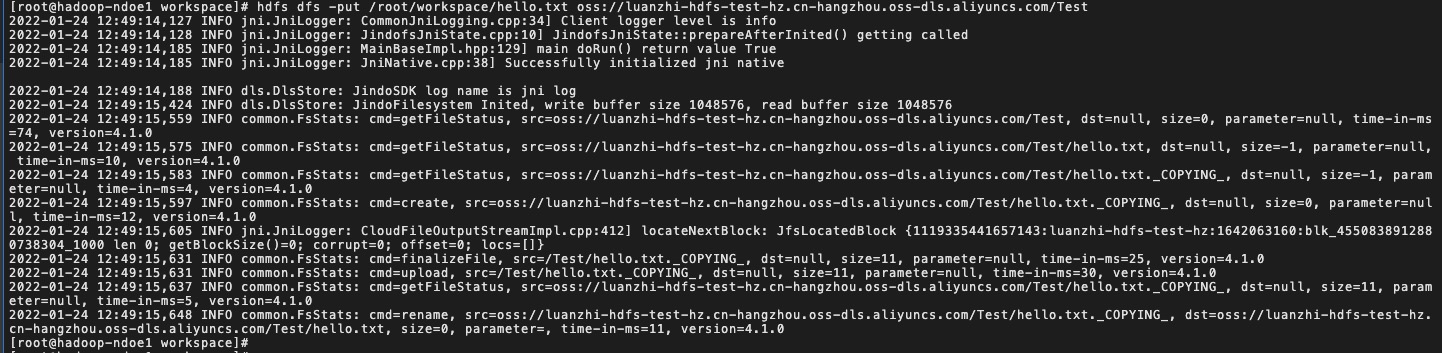
利用hdfs dfs -put指令上传本地文件到JindoFS服务
用例:hdfs dfs -put oss://./Test
hdfs dfs -put /root/workspace/hello.txt oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/Test
检查文件或许目录信息
在文件或许目录创立完之后,能够检查指定途径下的文件/目录信息。hdfs dfs没有进入某个目录下的概念。在检查目录和文件的信息的时分需求给出文件/目录的绝对途径。 指令:ls 用例:hdfs dfs -ls oss://./Test
hdfs dfs -ls /root/workspace/hello.txt oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/Test

检查文件的内容
有时分咱们需求检查一下在JindoFS服务文件的内容。hdfs dfs指令支撑咱们将文件内容打印在屏幕上。(请留意,文件内容将会以纯文本方式打印出来,假如文件进行了特定格局的编码,请运用HDFS的JavaAPI将文件内容读取并进行相应的解码获取文件内容) 用例:hdfs dfs -cat oss://./Test/helloworld.txt
hdfs dfs -cat /root/workspace/hello.txt oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/Test/hello.txt

仿制目录/文件
有时分咱们需求将JindoFS服务的一个文件/目录拷贝到另一个位置,并且坚持源文件和目录结构和内容不变。 用例:hdfs dfs -cp oss://./Test/subdir oss://./TestTarget/sudir2
移动目录/文件
在许多大数据处理的比如中,咱们会将文件写入一个暂时目录,然后将该目录移动到另一个位置作为终究成果。源文件和目录结构和内容不做保存。下面的指令能够完结这些操作。 用例:hdfs dfs -mv oss://./Test/subdir oss://./Test/subdir1
下载文件到本地文件体系
某些状况下,咱们需求将OSS文件体系中的某些文件下载到本地,再进行处理或许检查内容。这个能够用下面的指令完结。 用例:hdfs dfs -get oss://./Test/helloworld.txt
删去目录/文件
在许多状况下,咱们在完结工作后,需求删去在JindoFS服务上的某些暂时文件或许抛弃文件。这些能够经过下面的指令完结。 用例:hdfs dfs -rm oss://./Test/helloworld.txt
参阅案例
''' 运用方法:拷贝本脚本到VPC内ECS中目录/root/workspace, 然后履行sh test_hdfs.sh,检查成果是否报错 ''' echo -e "\n\n创立目录lz-test...." hdfs dfs -mkdir oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/lz-test echo -e "\n\n检查根目录...." hdfs dfs -ls oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/ echo -e "\n\n上传文件test.txt...." echo "hello jack" >> test.txt hdfs dfs -put test.txt oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/lz-test/test.txt echo -e "\n\n删去本地测验文件test.txt...." rm test.txt echo -e "\n\n检查上传到bucket的文件内容...." hdfs dfs -cat oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/lz-test/test.txt echo -e "\n\n下载文件到本地...." hdfs dfs -get oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/lz-test/test.txt echo -e "\n\n检查下载到本地的文件内容...." cat test.txt echo -e "\n\n删去本地测验文件...." rm test.txt echo -e "\n\n删去测验目录lz-test...." hdfs dfs -rm -R oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/lz-test echo -e "\n\n检查根目录与子目录...." hdfs dfs -ls -R oss://luanzhi-hdfs-test-hz.cn-hangzhou.oss-dls.aliyuncs.com/